5. Dados Conectados
Nos capítulos anteriores deste guia vimos a evolução da Web de Documentos na direção de uma Web de Dados, e as tecnologias envolvidas em agregar semântica de forma a auxiliar a manipulação dessas informações por parte das aplicações. O horizonte que se deseja alcançar é o de um banco de dados global, onde um conjunto crescente de informações possa ser acessado por um conjunto diversificado de aplicações com os mais diferentes propósitos.
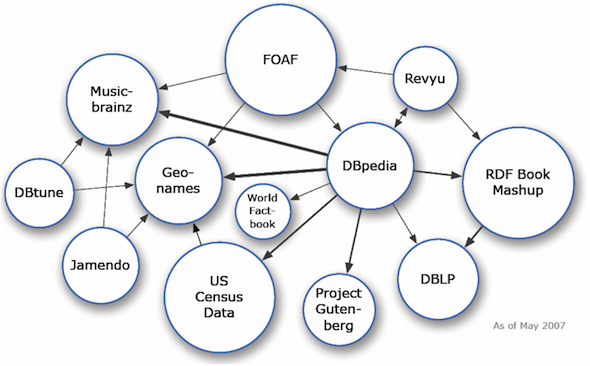
Dados são publicados na Web por diferentes pessoas e estão armazenados em diferentes repositórios espalhados pelo mundo. Para facilitar a construção desse banco de dados global é preciso que se estabeleça uma forma padrão de conexão entre esses dados. Neste capítulo serão apresentados os princípios do que se denominou Dados Conectados. A aplicação desse conceito se expande de forma veloz e a sua evolução costuma ser ilustrada pela figura de uma nuvem, a nuvem da LOD ( Linked Open Data ) [43], que mostra um conjunto de nós que representam conjuntos de dados abertos, e links que representam as conexões estabelecidas entre esses conjuntos de dados. As figuras 5.1 e 5.2 mostram a nuvem em 2007 e 2014, respectivamente.

{kind=link}

É fácil perceber a grande expansão da nuvem e a importância do conjunto de dados da DBpedia (nó central da nuvem de 2014, com o maior número de conexões), que contém dados representados em RDF relativos às informações contidas nas caixas de informações dos artigos da Wikipedia.
5.1 Os 4 Princípios
A ideia de se agregar semântica aos dados não é suficiente para a criação de um banco de dados global. Para tal, é preciso que esses dados sejam conectados. Em 2006, Tim Berners-Lee definiu uma lista de 4 princípio s [44] para a conexão desses dados:
• Use URIs para identificar as coisas (recursos).
• Use HTTP URIs, de forma a possibilitar que as pessoas possam procurar essas coisas na Web.
• Quando alguém procurar por uma URI, forneça informações relevantes utilizando os padrões (RDF, SPARQL).
• Inclua links para outras URIs, de forma a possibilitar que mais coisas possam ser descobertas.
Como vimos anteriormente, as URIs são utilizadas para a identificação de recursos, que podem representar qualquer coisa, concreta ou abstrata. O modelo RDF define uma forma de se representar o conhecimento por meio de triplas que podem definir valores literais para as propriedades, ou, então, estabelecer relacionamentos entre os diversos recursos, as diversas coisas.
O fato de utilizarmos HTTP URIs, permite que essa identificação seja utilizada para uma requisição via Web. O que o terceiro princípio estabelece é que uma vez feita uma requisição utilizando uma dessas URIs (dereferenciação), o servidor responsável por atender a esse pedido deve retornar algum tipo de informação relacionada ao recurso identificado pela URI. Como vimos na seção que apresenta os conceitos de SPARQL, o retorno de uma requisição desse tipo poderia ser algo do tipo do comando DESCRIBE, onde são retornadas as triplas onde o recurso identificado pela URI pode aparecer como sujeito, predicado ou objeto. Uma forma mais simples, seria ter um arquivo rdf estático com as triplas consideradas úteis. Esse princípio não estabelece o que deve ser retornado. Essa decisão é uma atribuição do servidor Web que atende a requisição.
O quarto e último princípio estabelece a conexão propriamente dita entre os dados. Ele estabelece que sempre que possível, um conjunto de dados deve fazer referência a outros conjuntos, de forma a permitir uma navegação entre os diversos nós da nuvem. Por exemplo, o site da DBpedia contém informações sobre recursos que representam pessoas, países, etc. Caso algum outro conjunto de recursos, por exemplo, o site da BBC Music , queira referenciar informações sobre os artistas que aparecem em suas programações, ele pode incluir links entre os seus recursos e os recursos da DBpedia. Ou seja, triplas contidas no conjunto de dados da BBC Music farão referência a URIs de recursos contidos em triplas da DBpedia.
5.2 As 5 Estrelas
A Web de Dados é atualmente um espaço heterogêneo onde diversos tipos de informações são publicados nos mais diversos formatos e estruturas de armazenamento. Temos dados armazenados em arquivos em diversos formatos, dados armazenados em bancos de dados e retornados em páginas Web, Web Services e Web APIs , dados armazenados em bancos de triplas, endpoints SPARQL, etc.
Como forma de orientar a publicação de dados abertos na Web, nessa nova visão semântica, Tim Berners-Lee sugeriu um esquema de classificação de 5 estrelas [45], onde é traçado um caminho evolutivo na direção desse universo de Dados Conectados, uma Web de Dados onde todas as informações estariam conectadas de acordo com os 4 princípios.
Essa escala é composta de 5 níveis:
1. Publique a sua informação na Web (qualquer que seja o formato) sob um tipo de licença de dados abertos.
2. Publique essa informação na forma de dados estruturados (por exemplo, uma planilha Excel ao invés de uma imagem digital de uma tabela).
3. Use formatos não proprietários (por exemplo, uma tabela CSV ao invés de uma planilha Excel).
4. Use URIs para identificar as coisas, de tal forma que as pessoas possam apontar para as suas informações.
5. Faça a conexão entre os seus dados e outros dados, de forma a prover um contexto maior para as informações.
Cada um desses níveis apresenta custos e benefícios que incluem, por exemplo, simplicidade do procedimento, conversões de dados, formação de pessoal qualificado, etc., tudo isso no interesse em caminhar na direção de um conjunto de dados semanticamente melhor descritos, e conectados com outros dados. A seguir é apresentado um exemplo 8 de como um mesmo conjunto de dados poderia ser publicado dentro de cada um dos níveis da classificação “5 Estrelas”.
A figura 5.3, apresenta um exemplo de uma publicação “1 Estrela”: uma imagem de uma tabela publicada em um arquivo pdf. Essa informação pode ser facilmente processada por humanos mas é de muito difícil entendimento por parte de uma aplicação.
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
A figura 5.4, apresenta a mesma informação publicada em uma planilha de um arquivo Excel, o que facilitaria o processamento dessa informação por parte das aplicações, porém ainda utilizando um formato proprietário, sendo portanto o caso de uma publicação “2 Estrelas”.
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
A figura 5.5, apresenta a mesma informação publicada em um arquivo no formato CSV (um formato não proprietário), sendo portanto o caso de uma publicação “3 Estrelas”.
Day,Lowest Temperature (C)
"Saturday, 13 November 2010",2
"Sunday, 14 November 2010",4
"Monday, 15 November 2010",7
A classificação “4 Estrelas” denota a passagem do nível de publicações para um estágio aderente à Web Semântica. No caso do exemplo utilizado, poderíamos associar os elementos das células às propriedades de determinados vocabulários. A figura 5.6 apresenta como uma página Web [46], poderia ser visualizada pelos usuários com as informações sobre as previsões meteorológicas dispostas em uma tabela.

A figura 5.7 apresenta parte do código HTML, com inserções de RDFa incluídas como forma de agregar informações semânticas aos dados. Um dos vocabulários definidos é o vocabulário meteo [47], que define um conjunto de propriedades para eventos meteorológicos.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<table border="1px">
<tr>
<th>Day</th>
<th>Lowest Temperature (°C)</th>
</tr>
<tr rel="meteo:forecast" resource="#forecast20101113">
<td>
<div about="#forecast20101113">
<span property="meteo:predicted"
content="2010-11-13T00
datatype="xsd:dateTime">Saturday, 13 November 2010
</span>
</div>
</td>
<td rel="meteo:temperature">
<div about="#temp20101113">
<span property="meteo:celsius"
datatype="xsd:decimal">2</span>
</div>
</td>
</tr>
...
A figura 5.8 apresenta as triplas extraídas da página, que também podem ser visualizadas utilizando o navegador RDF Graphite [48].
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix meteo: <http://purl.org/ns/meteo>
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
rdf:type meteo:Place ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 .
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
A classificação “5 Estrelas” denota a inserção das informações no universo de Dados Conectados. No caso do exemplo utilizado, foi feita uma conexão dos dados publicados na página com dados publicados sobre a cidade de Galway na DBPedia, utilizando a propriedade “owl:sameAs”, que indica que as duas URIs representam uma mesma coisa. Foi também criado um novo recurso (“#temp”) que faz a conexão de “temperatura” com informações definidas na DBpedia.
As figuras 5.9 e 5.10 apresentam as novas inserções, em relação ao exemplo de “4 Estrelas”.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Galway">
</span>
<table border="1px">
<tr>
<th>Day</th>
<th>
<div about="#temp">Lowest
<a rel="rdfs:seeAlso"
href="http://en.wikipedia.org/wiki/Temperature"
resource="http://dbpedia.org/resource/Temperature">
Temperature
</a>
(<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Celsius">
°C</span>)
</div>
</th>
</tr>
...
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix dbp: <http:/dbpedia.org/resource/> .
@prefix meteo: <ttp://purl.org/ns/meteo> .
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
df:type meteo:Place ;
owl:sameAs dbp:Galway ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 ;
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp
owl:sameAs dbr:Celsius ;
rdfs:seeAlso dbr:Temperature .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
5.3 Linked Data API
Um dos 4 princípios de Dados Conectados estabelece que quando é feito o acesso a uma URI de um recurso, por exemplo, uma escola, sejam retornadas informações relevantes sobre o recurso identificado (dereferenciação). Essas informações podem estar armazenadas, por exemplo, em arquivos estáticos contendo o conjunto de triplas que o servidor Web entende que sejam relevantes como informações sobre o recurso. Porém, muitas vezes, essas informações são construídas de forma dinâmica a partir de consultas a um SPARQL endpoint . Isso implica que os usuários das consultas SPARQL devem possuir um entendimento do esquema dos dados e dos vocabulários utilizados, nem sempre de fácil compreensão.
A idéia da Linked Data API (LD API) [49] é fornecer uma forma fácil de acessar Dados Conectados via Web, permitindo que conjuntos de recursos sejam expostos como URIs, fáceis de consultar, podendo ser filtradas, paginadas, ordenadas, utilizando parâmetros de consulta bastante simples. A LD API suporta diversos formatos de resultados, incluindo JSON, XML, RDF/XML e Turtle.
A LD API é uma especificação para um camada intermediária de software que se apoia sobre um SPARQL endpoint e oferece uma Web API para acessar os dados. O mapeamento é configurado pelo administrador do servidor de dados e atende a padrões de nomenclatura, como, por exemplo, http://orcamento.dados.gov.br/doc/{ano}/ItemDespesa, onde {ano} pode ser substituído de forma a obter os resultados específicos para uma determinada data: http://orcamento.dados.gov.br/doc/2013/ItemDespesa. A figura 5.11 apresenta a consulta que seria necessária para a obtenção das triplas relativas a essa informação.
PREFIX loa: http://vocab.e.gov.br/2013/09/loa#>
SELECT ?item
WHERE {
?item loa:temExercicio [loa:identificador 2013]. } OFFSET 0 LIMIT 6
Dessa forma, podem ser especificados padrões de URIs que aceitam como parâmetros informações que são definidas na URI para acesso aos recursos. Por exemplo, o site que permite o acesso a dados do orçamento federal brasileiro [50] aceita os padrões de URIs apresentados na figura 5.12 .
A LD API é uma especificação de código aberto e existem alguns produtos que a implementam, entre eles, o Elda [51] da Epimorphics.
/doc/{ano}/Acao
/doc/{ano}/Acao/{codigo}
/doc/{ano}/Atividade
/doc/{ano}/Atividade/{codigo}
/doc/{ano}/CategoriaEconomica
/doc/{ano}/CategoriaEconomica/{codigo}
/doc/{ano}/ElementoDespesa
/doc/{ano}/ElementoDespesa/{codigo}
/doc/{ano}/Esfera
/doc/{ano}/Esfera/{codigo}
/doc/{ano}/Exercicio
/doc/{ano}/Exercicio/{identificador}
/doc/{ano}/FonteRecursos
/doc/{ano}/FonteRecursos/{codigo}
/doc/{ano}/Funcao
/doc/{ano}/Funcao/{codigo}
/doc/{ano}/GrupoNatDespesa
/doc/{ano}/GrupoNatDespesa/{codigo}
/doc/{ano}/IdentificadorUso
/doc/{ano}/IdentificadorUso/{codigo}
/doc/{ano}/ItemDespesa
/doc/{ano}/ItemDespesa/{codigo}
/doc/{ano}/ModalidadeAplicacao
/doc/{ano}/ModalidadeAplicacao/{codigo}
/doc/{ano}/OperacaoEspecial
/doc/{ano}/OperacaoEspecial/{codigo}
/doc/{ano}/Orgao
/doc/{ano}/Orgao/{codigo}
/doc/{ano}/PlanoOrcamentario
/doc/{ano}/PlanoOrcamentario/{codigo}
/doc/{ano}/Programa
/doc/{ano}/Programa/{codigo}
/doc/{ano}/Projeto
/doc/{ano}/Projeto/{codigo}
/doc/{ano}/ResultadoPrimario
/doc/{ano}/ResultadoPrimario/{codigo}
/doc/{ano}/Subfuncao
/doc/{ano}/Subfuncao/{codigo}
/doc/{ano}/Subtitulo
/doc/{ano}/Subtitulo/{codigo}
/doc/{ano}/UnidadeOrcamentaria
/doc/{ano}/UnidadeOrcamentaria/{codigo}
5.4 Exemplos
Nesta seção será apresentada uma seleção de exemplos de implementações de Dados Conectados.
5.4.1 DBpedia
A DBpedia [52] trata a Wikipedia como um banco de dados e tem como objetivo extrair informações estruturadas da Wikipedia e tornar essas informações disponíveis na Web. A DBpedia permite fazer consultas sofisticadas aos dados estruturados contidos nos artigos da Wikipedia e relacionar os diferentes conjuntos de dados na Web aos artigos da Wikipedia. Os artigos da Wikipedia consistem principalmente de texto livre, mas também contêm diversos tipos de informações estruturadas, tais como caixas de informações, informações de categorização, imagens, coordenadas geográficas e links para páginas da Web.
O projeto DBpedia extrai vários tipos de informações estruturadas de edições da Wikipedia em 125 idiomas e combina essas informações em uma grande base de conhecimento. Cada entidade (recurso) no conjunto de dados da DBpedia é denotado por uma URI dereferenciável, na forma “http:dbpedia.org/resource/{nome}”, onde “{nome}” é derivado da URL do artigo origem da Wikipedia, que tem a forma “http://en.wikipedia.org/wiki/{nome}”. Assim, cada entidade da DBpedia está conectada diretamente a um artigo da Wikipedia. Cada {nome} de entidade DBpedia retorna uma descrição de um recurso na forma de um documento Web.
Por exemplo, o recurso “ http:dbpedia.org/resource/Tim_Berners-Lee ” da DBpedia está relacionado ao artigo “ http://en.wikipedia.org/wiki/Tim_Berners-Lee ” da Wikipedia. As figuras 5.13 e 5.14 apresentam, respectivamente, a página da Wikipedia de Tim Berners-Lee e a caixa de informações, em destaque. As figuras 5.15 e 5.16 apresentam, respectivamente, a página da DBpedia de Tim Berners-Lee (recurso Tim_Berners-Lee) e o destaque de algumas das propriedades e valores extraídos da página da Wikipedia. As informações da DBpedia podem ser obtidas em diferentes formatos. A figura 5.17 apresenta parte das triplas em formato Turtle.




@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix dbpprop: <http://dbpedia.org/property/> .
dbpedia:Tim_Berners-Lee
rdf:type foaf:Person ;
foaf:name "Sir Tim Berners-Lee"@en ;
dbpprop:awards "*OM \n*KBE \n*OBE \n*RDI \n*FRS \n*FREng"@en ;
foaf:depiction ;
<http://commons.wikimedia.org/wiki/Special:FilePath/Tim_Berners-Lee_ 2012.jpg>;
dbpprop:birthName "Timothy John Berners-Lee"@en ;
dbpprop:dateOfBirth "1955-06-08+02:00"^^xsd:date ;
dbpprop:placeOfBirth "London, England"@en ;
dbpprop:occupation dbpedia:Computer_scientist ;
dbpedia-owl:employer
dbpedia:Massachusetts_Institute_of_Technology ,
dbpedia:World_Wide_Web_Consortium ,
dbpedia:University_of_Southampton ,
dbpedia:Plessey ;
dbpedia-owl:title "Professor"@en ;
dbpprop:partner "Rosemary Leith"@en ;
dbpedia-owl:parent
dbpedia:Mary_Lee_Woods ,
dbpedia:Conway_Berners-Lee ;
dc:description "British computer scientist, known as the inventor of the World Wide Web" ;
...
dbpedia:Mary_Lee_Woods dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:Conway_Berners-Lee dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web_Consortium dbpprop:leaderName
dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:Libwww dbpprop:author dbpedia:Tim_Berners-Lee .
dbpedia:ENQUIRE dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:WorldWideWeb dbpedia-owl:developer dbpedia:Tim_Berners-Lee .
Os dados contidos na DBpedia também podem ser obtidos por meio de consultas a um SPARQL endpoint [53], implementado com a aplicação Virtuoso da Openlink. Os dados podem ser acessados por meio de diversas formas, incluindo o construtor de consultas Leipzig [54], o construtor de consultas interativo Openlink (iSPARQL) [55], e o explorador de consultas SNORQL [34].
Existem diversas aplicações [56] que fazem uso das informações contidas na DBpedia, como, por exemplo, o DBpedia Spotlight [57], que a partir de um texto fornecido em estilo livre sugere links para os recursos da DBpedia. Tomando como exemplo o texto da figura 5.18, o Spotlight sugere o texto da figura 5.19 com diversos links para a DBpedia (em português), incluindo um link para o recurso que descreve a World Wide Web [58] .
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL ou TBL) (Londres, 8 de junho de 19551 ) é um físico britânico, cientista da computação e professor do MIT. É o criador da World Wide Web (Rede Mundial de Computadores - Internet), tendo feito a primeira proposta para sua criação a 25 de março de 1989. 2 em 25 de dezembro de 1990, com a ajuda de Robert Cailliau e um jovem estudante do CERN, implementou a primeira comunicação bem-sucedida entre um cliente HTTP e o servidor através da internet.
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL ou TBL) (Londres, 8 de junho de 19551 ) é um físico britânico, cientista da computação e professor do MIT. É o criador da World Wide Web (Rede Mundial de Computadores - Internet), tendo feito a primeira proposta para sua criação a 25 de março de 1989. 2 em 25 de dezembro de 1990, com a ajuda de Robert Cailliau e um jovem estudante do CERN, implementou a primeira comunicação bem-sucedida entre um cliente HTTP e o servidor através da internet.
5.4.2 Dados Conectados da Biblioteca da Espanha
O projeto datos.bne.es [59] da Biblioteca Nacional da Espanha e do Grupo de Engenharia de Ontologias [60] da Universidade Politécnica de Madri tem como público-alvo tanto os usuários finais da biblioteca, como os desenvolvedores de software especialistas em Web Semântica. É um projeto piloto que visa propor uma abordagem e uma exploração dos dados bibliográficos diferente dos catálogos tradicionais, propondo uma experiência de navegação nova para os diferentes recursos da biblioteca, enriquecendo seus próprios dados com dados externos.
Os dados podem ser acessados a partir do portal ou de uma interface SPARQL [61]. Além disso, dumps completos dos dados também podem ser obtidos. Os dados definidos na aplicação seguem o modelo de dados de uma ontologia [62] desenvolvida pelo Grupo de Engenharia de Ontologias da Universidade Politécnica de Madri.
As figuras 5.20 e 5.21 apresentam, respectivamente, a página inicial do projeto e a página de busca de autores, de obras ou de temas. As figuras 5.22 e 5.23 apresentam a página resultante da busca pelo autor “Miguel de Cervantes” e a seleção da sua obra “ Dom Quijote de la Mancha”. A figura 5.24 apresenta um destaque da figura 5.23, onde é possível ver como as informações são apresentadas como um conjunto de valores de propriedades do recurso “ Dom Quijote de la Mancha ”.





5.4.3 BBC Things
BBC Things [63] usa tecnologias de Web Semântica que permitem o acesso a coisas que são importantes para o público do grupo BBC, tais como pessoas, lugares, organizações, competições esportivas, tópicos de estudo, etc.. A BBC tem um conjunto próprio de ontologias [64] que definem os tipos de coisas que podem ser consultados em BBC Things .
As figuras 5.25 e 5.26 apresentam a página HTML resultante de uma consulta ao tópico “Madonna” e o código exportado em Turtle. O código HTML retornado pela consulta tem as informações da triplas associadas ao recurso embutidas em RDFa.

@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix core: <http://www.bbc.co.uk/ontologies/coreconcepts/> .
@prefix mo: <http://purl.org/ontology/mo/> .
@base <http://www.bbc.co.uk/things/> .
:aead1a21-a0da-47a0-a1b3-ee8957960805#id>
a mo:MusicArtist ;
rdfs:label "Madonna"@en-gb ;
core:preferredLabel "Madonna"@en-gb ;
core:disambiguationHint "Music Artist"@en-gb ;
core:primaryTopicOf
<http://www.bbc.co.uk/music/artists/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://www.madonna.com/> ,
<http://en.wikipedia.org/wiki/Madonna_(entertainer)> ,
<http://www.imdb.com/name/nm0000187/> ;
core:sameAs
<http://dbpedia.org/resource/Madonna_(entertainer)> ,
<http://www.wikidata.org/entity/Q1744> ,
<http://musicbrainz.org/artist/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://rdf.freebase.com/ns/m.01vs_v8> .
5.4.4 Orçamento Federal do Governo Brasileiro
A Lei Orçamentária Anual (LOA) estima as receitas e fixa as despesas do Governo para o ano subseqüente, e fornece a previsão das ações planejadas pelo governo para um exercício financeiro, que corresponde ao período de 1º de janeiro a 31 de dezembro. O Orçamento anual visa concretizar os objetivos e metas propostas no Plano Plurianual (PPA), segundo as diretrizes estabelecidas pela Lei de Diretrizes Orçamentárias (LDO).
O Governo Federal publicou o orçamento federal em formato RDF (no período de 2000 a 2013), a fim de dar maior transparência e acesso aos dados, de forma que cidadãos e organizações interessados em conhecer melhor os dados do orçamento federal possam realizar pesquisas e análises de forma veloz e eficiente. A estratégia adotada no projeto “Orçamento Federal em Formato Aberto”, do Governo Federal, foi criar uma ontologia [65] com base na classificação da despesa do orçamento federal, contemplando as categorias e conceitos especificados no Manual Técnico de Orçamento [66].
As informações do orçamento podem ser obtidas a partir do catálogo de dados abertos do governo federal [67]. É possível obter acesso a diversos conjuntos de dados:
• Dumps dos dados por ano (2000 a 2013).
• Acesso aos diversos padrões de URIs [68], por exemplo, a lista dos itens de despesa de 2014: http://orcamento.dados.gov.br/doc/2014/ItemDespesa .
• Consultas ao SPARQL endpoint [69] do projeto, por exemplo:
SELECT ?nomeFuncao (sum (?DotacaoInicial)) as ?soma
WHERE
{ ?item rdf:type loa:ItemDespesa .
?item loa:temExercicio [loa:identificador 2014] .
?item loa:temFuncao [rdfs:label ?nomeFuncao] .
?item loa:valorDotacaoInicial ?DotacaoInicial.
?item loa:valorDotacaoInicial ?DotacaoInicial. }
GROUP BY ?nomeFuncao
5.4.5 Bio2RDF
Pesquisadores biológicos são frequentemente confrontados com a inevitável tarefa de ter que integrar seus resultados experimentais com resultados de outros pesquisadores. Essa tarefa geralmente envolve uma tediosa busca manual, e a assimilação de diversas coleções isoladas de dados de ciências da vida, hospedados por vários provedores independentes. Esses provedores incluem organizações tais como o Centro Nacional para Informação Biotecnológica (NCBI) e o Instituto de Bioinformática Europeu (EBI), que fornecem dezenas de conjuntos de dados enviados por usuários, assim como instituições menores, como o grupo Donaldson que publica iRefIndex3, um banco de dados de interações moleculares agregados de 13 fontes de dados diferentes.
Com milhares de bancos de dados biológicos e centenas de milhares de conjuntos de dados, a capacidade de encontrar dados relevantes é dificultada por interfaces de banco de dados não padronizadas e um número enorme de formatos de dados heterogêneos. Além disso, metadados sobre esses provedores de dados biológicos (informações do conjunto de dados, fontes dos dados, controle de versão, informações de licenciamento, data de criação, etc.) são muitas vezes difíceis de obter. Tomados em conjunto, a incapacidade de navegar facilmente pelos dados disponíveis apresenta uma barreira enorme para sua reutilização.
Bio2RDF [70] é um projeto de dados abertos que usa tecnologias da Web Semântica para tornar possível a consulta distribuída de dados integrados de ciências da vida. Desde o seu início, Bio2RDF tem feito uso de RDF e RDFS para unificar a representação de dados obtidos de diversos campos (moléculas, enzimas, doenças, etc.) e dados biológicos armazenados em formatos heterogêneos (arquivos-texto, arquivos CSV, formatos específicos de bancos de dados, XML, etc.). Uma vez convertidos para RDF, este dados biológicos podem ser consultados usando SPARQL, que pode ser utilizado para a realização de consultas federadas em diversos SPARQL endpoints .
Atualmente, Bio2RDF comporta 35 conjuntos de dados, entre eles o DrugBank [71], que é um banco de recursos bioinformáticos e químico-informáticos que combina dados detalhados sobre drogas (química, farmacologia, farmacêutica, etc.), com informações tais como sequência, estrutura, etc. Cada um dos conjuntos de dados possui um SPARQL endpoint e utiliza conjuntos de vocabulários próprios desse domínio. Em BioPortal [72] é possível visualizar a enorme lista de vocabulários específicos para cada uma da áreas.
As Figuras 5.27 e 5.28 apresentam, respectivamente os resultados de uma consulta a “Glutahione” no site DrugBank [73] e no SPARQL endpoint [74] associado.

