2 – Estruturação de Dados e Dados Abertos Conectados
Introdução
Como descrevemos no Capítulo 1, dados abertos são dados que podem ser livremente utilizados, reutilizados e redistribuídos por qualquer pessoa - sujeitos, no máximo, à exigência de citar a fonte original e compartilhar com as mesmas licenças em que as informações foram inicialmente apresentadas. Vimos também no capítulo anterior que a disponibilização destes dados é classificada de acordo com o “Sistema de 5 Estrelas”: quanto maior o número de estrelas, melhor é a visibilidade, integração e usabilidade destes dados tanto por pessoas quanto por máquinas.
Neste capítulo, estamos interessados em aprofundar os conhecimentos sobre os dados abertos estruturados e conectados (ou Linked Data) seguindo o “Sistema de 5 Estrelas”. Queremos assim, apresentar ao leitor alguns conhecimentos técnicos para utilizar modelos e padrões que viabilizam o uso dos dados estruturados disponíveis na Web para busca e navegação de forma (semi-) automática com o apoio de programas de computador. Esses modelos e padrões para disponibilização dos Dados Conectados são a base para se construir a Web de Dados e, por consequência, prover um dos “pilares” necessários para consolidação da Web Semântica.
A Web de Dados tem como objetivo fazer um contraponto a Web de Documentos (vide Capítulo 1). Na Web de Documentos, os recursos como páginas web, figuras e vídeos estão conectados por meio de URIs 18. Essa conexão é fundamental para fazer associações entre diferentes recursos disponíveis na Web e para consumo massivo da informação destes recursos por pessoas (agentes humanos). Assim, podemos dizer que na Web de Documentos são os recursos, e não as informações contidas nestes recursos, que estão conectados. Porém, para que um programa de computador possa utilizar as informações contidas na Web, é necessário que estejam disponíveis para ele conhecimentos adicionais que caracterizem os recursos, como eles se relacionam e quais dados estão contidos neles. Neste contexto, surge a Web de dados, na qual os recursos estão conectados também por URIs, porém informações adicionais são disponibilizadas para permitir que as máquinas possam compreender melhor os dados contidos nestes recursos e o “significado” de determinada relação entre dois ou mais recursos. Por exemplo, na Figura 2.1 (inspirada no trabalho de (Chen, 2007)) temos em 2.1(a) a Web de Documentos na qual o relacionamento entre páginas é feito por meio de links (i.e. URIs) entre documentos. Já em 2.1(b) temos a Web de dados que apresenta links entre páginas e informações adicionais que deixam explícito a relação entre os dados contidos nos documentos. Neste pequeno grafo de (b), os dados mais importantes desta página são apresentados como vértices (e.g. Brasília) enquanto o significado das relações entre estes dados é apresentado nas arestas (e.g. Capital-do).


As informações adicionais que descrevem os dados contidos nos documentos são chamadas de metadados, ou seja, dados sobre dados. Os metadados em conjunto com métodos de modelagem conceitual da informação, que serão apresentadas no próximo capítulo, são essenciais para publicação de dados conectados. Ao longo deste capítulo apresentaremos, por meio de exemplos, os conceitos técnicos necessários para criar e trabalhar com metadados e a Web de dados. Estes conceitos permitirão que o leitor tenha a capacidade de produzir dados abertos de alta qualidade utilizando uma das tecnologias recomendadas pelo W3C conhecida como RDF 19 (Resource Description Framework).
2.2 Estruturação de Dados e Dados Abertos Conectados
Os Dados Conectados como apresentados na seção anterior fazem da Web um banco de dados global que podemos chamar de web de dados. A partir deste banco de dados global, os desenvolvedores podem criar e executar consultas que buscam dados de diferentes fontes e as combinar para prover algum tipo de informação útil. Este tipo de consulta é impossível (ou inviável) quando se pensa em tecnologias de gerenciamento de bancos de dados tradicionais (Wood, et al., 2014).
Ao se observar a relação entre a estruturação de dados e os Dados Conectados (não necessariamente Dados Abertos Conectados), conforme mostramos na Figura 1.10 (vide Cap 1), podemos compreender que um dos problemas para a sustentabilidade da Web de Dados são os Dados Estruturados. Frisamos, contudo, que neste capítulo focaremos somente nos conceitos relacionados à estruturação dos dados da Web, que permitem a representação de dados conectados abertos conforme mostra o bloco à direita da Figura 1.10.
Nesse contexto, podemos destacar diversos aspectos a partir deste ecossistema de Dados Conectados e estruturados:
- É possível utilizar diferentes formatos de estruturação de dados na Web;
- Os Dados Conectados possuem uma estrutura de dados baseada em RDF;
- Existem diferentes formatos RDF para estruturação de dados;
- Os Dados Conectados podem ser considerados como um subconjunto da Web Semântica.
É importante salientar que não há como ter Dados Conectados sem fazer a utilização do modelo de dados RDF 20. No entanto, como vimos no Capítulo 1, há uma série exigências que precisam ser atendidas para que os dados sejam estruturados no modelo RDF. No que tange os Dados Abertos Conectados, as 5 estrelas para Dados Abertos Conectados mostram que quanto mais aumentamos o número de estrelas, melhor serão os dados abertos. Entretanto, só podemos efetivamente considerar que os dados publicados são do tipo “Dados Conectados” quando estes recebem pelo menos quatro estrelas. Assim, na seção seguinte faremos uma explicação mais detalhada sobre o sistema 5 estrelas, por meio de exemplos.
2.2.1 Padrões de Representação
A preparação dos dados para que os mesmos passem de Dados Abertos para Dados Abertos Conectados pode ser feita por meio de uma série de transformações intermediárias. Conforme vimos no Capítulo 1, a Figura 2.2 apresenta o esquema de distribuição 5 estrelas para Dados Abertos, proposto por Tim Berners-Lee, em 2010 (Berners-Lee, 2010).

Para exemplificar, vejamos o cenário disponível em (5 Start Open Data, 2012). Como poderíamos abrir os dados sobre a temperatura da cidade Irlandesa, Galway, conforme Tabela 2.1.
TABELA 2.1
EXEMPLO PARA DEMOSTRAR ESQUEMA DE 5 ESTRELA DOS DADOS ABERTOS
| Day | Lowest Temperature (°C) |
|---|---|
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
A abertura pode ocorrer de acordo com o esquema das 5 estrelas. De acordo com as estrelas, a única exigência para que o dado seja considerado aberto é que sejam disponibilizados com licenças abertas. Mesmo um documento sendo publicado em PDF ou PNG, se o mesmo utiliza uma licença aberta, então ele pode ser considerado um dado aberto.
Como exemplo para dados abertos com apenas uma estrela, veja o URI abaixo. Este URI abre um arquivo PDF contendo dados de temperatura em Galway, na Irlanda. Ou seja, só há a necessidade de disponibilizar o identificador para o recursos em formato PDF.
http://5stardata.info/gtd-1.pdf
É importante enfatizar que hádiferentes licenças sendo utilizadas pela comunidade de Dados Abertos. Como exemplos de licenças, citamos as licenças da Open Data Commons (Open Data Commons, 2014), como:
- Public Domain Dedication and License (PDDL);
- Attribution License (ODC-By);
- Open Database License (ODC-ODbL).
Apesar do dado do exemplo apresentado ter sido publicado com licença aberta, o dado está “trancado” em um documento PDF. Ou seja, ele não pode ser manipulado e reutilizado facilmente em outros contextos e situações. Isto faz com que o acesso ao dado dentro do documento fique bastante difícil, tornando complicado o seu uso e acesso por máquinas (e até por pessoas dependendo da complexidade e quantidade dos dados disponibilizados).
A segunda estrela considera que, além do dado estar sob licença aberta, o mesmo deverá utilizar um formato de dado estruturado. No entanto, para que o dado possua duas estrelas, pode-se disponibilizá-lo utilizando formatos proprietários para estruturação dos dados. Por exemplo, são considerados dados de duas estrelas aqueles publicados com licença aberta e disponibilizados no formato de uma planilha Excel em XLS, formato proprietário cuja detentora de seus direitos é a Microsoft. No URI abaixo temos o exemplo de dados abertos publicados com duas estrelas para o nosso exemplo sobre a disponibilização de dados da temperatura de Galway:
http://5stardata.info/gtd-2.xls
Diferente da abertura dos dados com uma estrela, o dado disponível em formato XLS pode ser acessado por máquina de forma menos complicada. Isso permite que os dados sejam utilizados mais facilmente tanto por pessoas, que podem utilizar, adaptar e integrar estes dados com outros dados disponíveis, quanto por máquinas que podem ler estes dados e manipulá-los mais livremente. Apesar do dado em formato XLS facilitar o consumo dos dados, existem ainda dois problemas identificados: 1) os dados continuam trancados em um documento; 2) o acesso ao dado dentro do documento XLS necessita de software proprietário.
A terceira estrela dos dados abertos é alcançada quando se faz a utilização de formatos abertos e não proprietários, como CSV (do inglês Comma-Separated Values, significando valores separados por vírgula). Através da publicação de dados em formato não proprietário, a manipulação dos dados fica muito mais simplificada e sem restrições dos softwares proprietários. O exemplo da temperatura de Galway publicado em formato três estrelas está disponível no link abaixo:
http://5stardata.info/gtd-3.csv
Os dados no documento CSV ficam disponíveis conforme explicitado abaixo.
| “Day”, | “Lowest Temperature (°C)” |
|---|---|
| “Saturday, 13 November 2010”, | 2 |
| “Sunday, 14 November 2010”, | 4 |
| “Monday, 15 November 2010”, | 7 |
Como podemos observar, o arquivo CSV faz o armazenamento de dados tabulares em um formato plain-text, ou sequência de caracteres. Este tipo de documento nada mais é que um formato de dados delimitador, no qual as colunas de uma tabela são separadas pelo caractere vírgula, enquanto os registros são separados por novas linhas do arquivo. A IETF, do inglês Internet Engineering Task Force, é o órgão responsável pelo desenvolvimento e melhoria da Internet, disponibiliza o RFC 4180, uma especificação para a descrição de dados tabulares em formato CSV.
A publicação em formato CSV apresenta um avanço no esquema de distribuição de 5 Estrelas. Contudo, o formato CSV não possui a riqueza para representar detalhes importantes e não permite que desenvolvedores possam criar programas de computador mais inteligentes que extraiam múltiplos catálogos de dados, manipule-os, visualize-os e os combine de maneira flexível. Apesar disso, a grande maioria dos dados disponíveis atualmente nos diversos bancos de dados públicos (e.x. http://data.gov.br/) estão neste formato. Devido a esse grande número de dados abertos em formato CSV, o W3C criou um grupo de trabalho (CSV on the Web) com o objetivo de definir um vocabulário para metadados em CSV e métodos padronizados para:
(a) encontrar os metadados via protocolo HTTP;
(b) encontrar os dados descritos pelos metadados através de uma API; e
(c) mecanismos de mapeamento de CSV para outros formatos como RDF e JSON.
A quarta estrela está relacionada com a utilização de URIs para identificar os recursos na Web. A grande vantagem da utilização de URIs é que eles podem ser encontrados e consumidos por outras pessoas e máquinas de forma muito mais simplificada do que a disponibilização em CSV. Ou seja, o URI nos permite compartilhar cada dado que estamos publicando. Há diversos formatos para representação destes dados (e.x. Atom e RSS), mas o tipo de formato que estamos interessados é o RDF. O link com o exemplo da temperatura contendo 4 estrelas está disponível em:
http://5stardata.info/gtd-4.html
Após ver este documento, você pode estar se perguntando: não é apenas mais uma página em HTML? Qual a novidade desta página? Por que a extensão do documento está em HTML e não em RDF como aconteceu com os outros formatos? Isto acontece porque documentos em formato RDF podem ser serializados e disponibilizados de diferentes formas. Uma delas é o RDFa (Resource Description File in Attributes) que adiciona uma série de atributos às tags HTML. Desta forma, ao invés de disponibilizar um arquivo com a extensão RDF, pode-se disponibilizar um arquivo HTML possuindo vários atributos de um documento RDF. Neste contexto, as informações sobre os dados ficam separadas das informações sobre como apresentar os dados. O código HTML contendo os atributos RDF são apresentados abaixo.


Fazendo uma leitura do código HTML da Figura 2.3, observamos na 6 linha que há três atributos sendo utilizados na tag < tr>, sendo eles rel, resource e class (este atributo global não está trazendo nenhuma informação adicional para a descrição das temperaturas). Uma lista de atributos utilizados em RDFa está disponível aqui. Observando assim os dois atributos da tag (<tr rel =quot; meteo:forecast " resource =" #forecast20101113 ">), temos:
• <tr> é uma tag HTML que representa uma linha da tabela; • rel é um atributo que define um relacionamento entre dois recursos. Neste exemplo, rel está sendo utilizado para indicar que esta linha possui um relacionamento com meteo:forecast. A utilização deste atributo não apresenta novas informações para apresentar um recurso no navegador, por exemplo, formatação de interface, no entanto fornece informações adicionais para máquinas poderem identificar e manipular um recurso; • meteo:forecast é um alias, nome curto ou pseudônimo, para descrever um recurso disponível no endereço http://purl.org/ns/meteo#forecast. Este alias é criado para que, ao invés de toda vez repetirmos o endereço web completo para cada identificador de documentos, seja possível definir um nome simples que reduz a complexidade do código e facilita a leitura. Neste caso em particular, o nome meteo é a abreviação do termo em inglês meteorology utilizado pelos criadores do documento. Se clicar com o botão direito no link http://5stardata.info/gtd-4.html e pedir para exibir o código fonte, encontrará a tag HTML com a identificação de meteo, conforme a última linha da Figura 2.4.
- resource é utilizado para identificar o recurso do relacionamento. É importante frisar que o relacionamento definido através deste atributo não fornecerá um link apresentado na página, mas sim um objeto que poderá ser utilizado por máquinas, neste caso #forecast20101113;
- #forecast20101113 é o objeto no qual identifica um determinado recurso. Ou seja, através de consultas a este recurso, os valores das colunas Day e Lowest Temperature °C identificadas pelas tag <TD> podem ser buscados.
É importante frisarmos que esta estrutura de descrição está disponível em todo o documento do exemplo acima, no qual outros atributos e recursos podem ser identificados, como about, meteo:temperature, xsd:dateTime, meteo:celsius, e assim por diante.
Toda esta descrição teve como objetivo apresentar ao leitor como podemos descrever e publicar nossos dados com 4 estrelas. Através deste tipo de publicação, os dados mais importantes do documento terão um URI que poderá ser utilizado por buscadores com diferentes propósitos. Através da disponibilização deste URI, é possível:
a) conectar e combinar estes dados com outros dados;
b) reusar estes dados em outros contextos;
c) melhorar a busca e a compreensão dos dados apresentados;
d) possibilitar inferência através de dados parciais;
e) permitir navegação entre documentos; entre outros.
Como acabamos de descrever, esta abordagem permite que os dados possam ser conectados e combinados com outros dados para melhorar ainda mais a identificação e compreensão dos mesmos. Fazer este tipo de conexão equivale a disponibilizar os seus dados com 5 estrelas. A única diferença dos dados abertos com 4 e 5 estrelas é que neste último os seus dados estarão conectados com dados de outras fontes. Segundo o mesmo exemplo, os dados de temperatura da cidade Irlandesa, Galway, com 5 estrelas podem ser identificados no link abaixo:
http://5stardata.info/gtd-5.html
Um tipo de dado que poderia ser útil a apresentar seriam informações sobre a cidade de Galway, na Irlanda ou até mesmo sobre o país. Observemos a seguir um trecho do código HTML em 5 estrelas.


No código da Figura 2.5, não há nenhum tipo de atributo adicional com relação ao código com 4 estrelas. Porém, ao se observar os valores que estão sendo descritos nos atributos, podemos ver que há diferença. Cada um deles é apresentado a seguir:
- owl:sameAs é uma propriedade pertencente à linguagem OWL (do Inglês Web Ontology Language ) que descreve que um recurso é igual a outro recurso. Neste caso, o código informa que meteo:Place#Galway (identificado pela linha <div id="data" about="#Galway>" typeof="meteo:Place">) é o mesmo que Galway identificado no link http://dbpedia.org/resource/Galway;
- http://dbpedia.org/resource/Galway é o recurso que foi identificado pela propriedade owl:sameAs;
- rdfs:seeAlso é uma propriedade do RDF-S (Resource Description Framework Schema) que tem por objetivo fornecer informação adicional ao que se está descrevendo no documento. Neste exemplo, a propriedade rdfs:seeAlso possui o valor http://en.wikipedia.org/wiki/Temperature, indicando assim que informações adicionais sobre o conceito de temperatura podem ser encontradas na Wikipedia através deste link;
- http://dbpedia.org/resource/Celsius está sendo utilizado neste documento da mesma forma que http://dbpedia.org/resource/Galway. Ou seja, está sendo utilizado para dizer que “°C” é a mesma coisa que http://dbpedia.org/resource/Celsius.
Você pode estar se perguntando qual o real benefício que esta descrição adicional trouxe para o documento. Caso você queira acessar os links da DBPedia para Galway, verá que muitos dados adicionais são fornecidos sobre a cidade de Galway, que antes não poderiam ser acessados automaticamente. Por meio desta identificação, é possível que máquinas possam, por exemplo, apresentar uma descrição da cidade, ou fotos turísticas da cidade, ou até mesmo disponibilizar um mapa com a localização exata da cidade.
Gostaríamos de salientar ao leitor que os exemplos apresentados no formato 4 e 5 estrelas requerem conhecimentos um pouco mais avançados sobre publicação de páginas Web, como HTML e também RDF. Não se preocupe caso não tenha acompanhado todas as minúcias do código, principalmente com relação ao RDF, pois essa foi sua primeira exposição a este conteúdo. Apesar de termos apresentado nesta subseção algumas das propriedades presentes no modelo RDF e também termos apresentado o formato de serialização RDFa, o modelo RDF apresenta muito mais riqueza e vale a pena conhecê-lo em mais detalhes. É isto que faremos na próxima subseção.
2.3 Representação de Dados Conectados com o Modelo RDF
O RDF (Resource Description Framework) equivale a uma linguagem de representação de informação na Web, permitindo que recursos possam ser descritos formalmente e sejam acessíveis por máquinas. Segundo (Shadbolt, et al., 2006), o objetivo do RDF é prover uma representação minimalista do conhecimento da Web.
A versão RDF 1.1 foi publicada em Fevereiro de 2014 e estendeu a versão 1.0 proposta em 2004. Esta nova versão já está disponível (Schreiber, et al., 2014). Nesta seção, abordaremos algumas das características presentes no RDF 1.1, como o modelo RDF, o seu vocabulário e suas formas de serialização. Esse conhecimento é importante para compreender a riqueza de expressividade que o RDF proporciona para descrever e representar a informação disponível na Web. Esse framework também é fundamental para entender os mecanismos necessários para criação de dados conectados de qualidade.
2.3.1 Modelo RDF
O primeiro aspecto a destacar do modelo RDF é que ele foi projetado para descrever recursos na Web. No entanto, é importante lembrar que a Web é um espaço de informação no qual os itens de interesse precisam ser identificados. Assim, cada recurso possui um identificador único e global (chamado de URI) para que o mesmo possa ser identificado na WWW. Na Figura 2.6 apresentamos um exemplo de como o recurso Oaxaca Weather Report é identificado pelo URI http://weather.example.com/oaxaca. Para entender o exemplo, é preciso entender a arquitetura da Web composta por três bases fundamentais, como descritas a seguir (Jacobs, et al., 2004):
1. Recurso único: como explicado anteriormente, os identificadores são utilizados para identificar os recursos. No exemplo abaixo o identificador é o URI que provê uma maneira simples e única de identificar recursos na Web, sendo caracterizado por três aspectos:
a) Uniformidade: utilização de recursos tanto no mesmo contexto quanto em contextos diferenciados;
b) Recurso: qualquer coisa que pode ser identificado por um URI, como um vídeo, imagem, serviço, documento, entre outros; e
c) Identificador: informação requerida para identificar e diferenciar um determinado recurso de qualquer outro.
Além disso, um URI pode ser classificado como:
i) URL (Uniform Resource Locator), onde basicamente define um localizador/endereço para um determinado recurso através de um protocolo existente e
ii) URN (Unified Resource Name) representa um nome para um determinado recurso, garantindo unicidade e persistência de forma global mesmo quando o recurso não está disponível. Finalmente, destacamos também o IRI (International Resource Identifier) que é uma generalização do URI. Diferente do URI que é baseado os caracteres ASCII, do inglês, American Standard Code for Information Interchange, o IRI amplia o número de caracteres Chineses (kanji) e Japoneses (hiragana e katakana), bem como os caracteres Cirílicos e Coreanos possam ser utilizados.
2. Interação: a Web possui uma arquitetura cliente-servidor. A comunicação na Web acontece através de protocolos padrões que permitem a troca de mensagens entre um Servidor web que implementa este protocolo e um Browser Cliente que envia a solicitação para o servidor. O Protocolo padrão utilizado na Web é o HTTP (Hypertext Transfer Protocol), e como o próprio acrônimo diz, é um protocolo de transferência de documentos hipertextos (e.x. HTML). Por exemplo, ao utilizarmos um browser (navegador), podemos digitar o URI http://weather.example.com, apresentado na Figura 2.6, com isso o navegador envia uma requisição do tipo HTTP GET para o Servidor web e o mesmo retorna uma mensagem contendo a representa ção do recurso.
3. Formatos: na comunicação cliente-servidor, o servidor irá retornar para o cliente (navegador) uma representação em um determinado formato. Cada formato de representação retornado para o cliente conterá informação de Metadados e Dados. Os metadados são os campos de cabeçalhos utilizados para identificar o formato de representação. No exemplo da Figura 2.6, o formato de representação é XHTML, que é identificado pelo Content-Type: application/xhtml+xml. Veremos mais a seguir que em RDF o valor do Content-Type será diferente, pois no modelo RDF temos diferentes formas de representação/serialização, como por exemplo Turtle (que possui Content-Type: text/turtle) ou JSON-LD (que possui Content-Type: application/ld+json).

Com este esclarecimento feito acerca das bases fundamentais da arquitetura da Web, apresentamos a Figura 2.7 que caracteriza o RDF
- Podemos observar que um recurso pode ser descrito por uma coleção de propriedades denominada descrição RDF
- Cada propriedade dentro da descrição RDF possui um tipo (property type) e um valor (value). Assim, qualquer recurso pode ser descrito com RDF e ser identificado por um URI. Inversamente, podemos pensar que um URI possui uma descrição em RDF que caracteriza um recurso disponível na Web (Iannella, 1998)
- A relação RDF com URI é um conceito chave para referenciar e descrever um recurso de forma única e não ambígua.

Além de auxiliar na descrição dos recursos disponíveis na Web de maneira mais precisa (descrição sintática), o RDF também oferece a possibilidade de descrever a relação e significados entre diversos recursos (descrição semântica). Assim, na próxima seção apresentaremos o conceito de triplas RDF que permite explicitar relaçõ es entre recursos.
1.1 Triplas
Como destacamos anteriormente, o modelo RDF permite a descrição dos recursos. Para descrever a relação entre recursos o RDF oferece uma estrutura de triplas do tipo <sujeito> <predicado> <objeto> (Cyganiak, et al., 2014) . O conjunto destas estruturas em tripla é chamado de Grafo RDF. Este grafo RDF pode ser visualizado como na Figura 2.8.

Esta Figura apresenta um grafo dirigido e acíclico, onde cada tripla é representada como nó-arco-nó. Desta forma, um grafo RDF normalmente possui múltiplas triplas que irão compor um documento RDF. Como exemplo de múltiplas triplas que são disponibilizadas num documento RDF, temos a Figura 2.9. Neste exemplo existem 6 triplas que representam a relação entre conceitos/recursos (i.e. vértices do grafo como Bob, Person, etc). Na relação <sujeito> <predicado> <objeto>, o sujeito e o objeto representam dois recursos que são relacionados por um predicado. Por exemplo, <Bob> < é amigo da> <Alice>, <Bob> representa um sujeito, que é um recurso, <Alice> representa o objeto que é outro recurso e < é amigo da> representa uma propriedade que relaciona <Bob> à <Alice>. Da mesma forma <A Mona Lisa> <foi criada por> <Leonardo Da Vinci> representa a relação entre o sujeito <A Mona Lisa> e seu criador, o objeto <Leonardo Da Vinci>, por meio da relação/propriedade <foi criada por>. A riqueza desta representação permite que um computador possa interpretar os dados representados por estas triplas. Contudo, para que isso seja completamente realizado precisamos garantir que cada um dos elementos do grafo sejam representados e referenciados de maneira única. E isso pode ser realizado utilizando os IRI.

1.2 IRIs
O Identificador de Recurso Internacional (ou IRI) é o responsável por identificar de maneira única um recurso na Web. Como um RDF é um Framework, onde todo recurso preferencialmente deve possuir um URI/IRI, então o IRI pode representar um <sujeito>, <predicado> ou <objeto>. Por exemplo, na Figura 2.9 a tripla <Bob> < é amigo da> <Alice> poderia ser representado utilizando IRIs como:
Sujeito: <http://example.com/Bob>
Predicado: <http://example.com/is_a_friend_of>
Objeto: < http://example.com/Alice>
É importante destacarmos que, da mesma forma como apresentado na Seção anterior, os dados aqui apresentados podem ser disponibilizados com 5 estrelas fazendo com que determinado dado seja conectado com outro dado. Ou seja, poderíamos reutilizar padrões e definições previamente desenvolvidos e consolidados. Assim, no exemplo, poderíamos fazer uso do vocabulário FOAF (Friend of a Friend) [http://xmlns.com/foaf/spec/], que tem por objetivo descrever relacionamento entre pessoas e informa ções na Web. Neste caso, o exemplo <Bob> < é amigo da> <Alice> poderia ser descrito da seguinte forma:
Sujeito: <http://example.com/Bob>
Predicado: < http://xmlns.com/foaf/0.1/knows>
Objeto: < http://example.com/Alice>
O mesmo poderia ocorrer para os diversos recursos da Figura 2.9, como apresentado na Tabela 2.2. A título de exemplo, de acordo com a tabela abaixo, podemos ver o reuso de três vocabulários, sendo eles presentes na FOAF, DBPedia 33 e a própria especificação do RDF.
TABELA 2.2
RECURSOS EM UM DOCUMENTO RDF E RECURSOS CANDIDATOS AO REUSO
| Recurso da Figura 2.9 | IRI (que podem ser reusados) |
|---|---|
| <Person> | http://xmlns.com/foaf/0.1/Person |
| <is a> | http://www.w3.org/1999/02/22-rdf-syntax-ns#type |
| <The Mona Lisa> | http://dbpedia.org/page/Mona_Lisa |
| <Leonardo da Vinci> | http://dbpedia.org/page/Leonardo_da_Vinci |
| <is about> | http://www.w3.org/1999/02/22-rdf-syntax-ns#about |
Outro vocabulário que poderia ser utilizado é o Dublin Core, que tem por objetivo descrever metadados, sendo bastante empregado para publicações científicas. Por exemplo, o recurso <foi criada por> está sendo utilizado para indicar que a obra Mona Lisa foi criada por Leonardo da Vinci. Neste contexto, o vocabulário Dublin Core possui o termo <http://purl.org/dc/terms/created> que poderia ser utilizado para indicar que Leonardo da Vinci criou Mona Lisa (relação inversa a inicialmente proposta, mas que possui o mesmo significado). Neste caso, toda a tripla seria construída através de IRI que foram reusadas. Essa reutilização dá maior robustez aos dados publicados na Web, reduzindo problemas de ambiguidade e de interpretação errônea.
Com as informações apresentadas nesta seção, conseguimos utilizar IRI para descrever recursos em triplas RDF, contudo, existem recursos/informações que não são associadas com uma IRI. Neste caso o RDF permite utilizar literais e tipos de dados para descrever uma informação.
1.3 Literais e Tipos de Dados
Os literais (usados em conjunto com os tipos de dados) podem ser compreendidos como todos os valores identificados num grafo RDF que não possuem um IRI associado. De acordo com a Figura 2.9, podemos identificar um literal que é a data“ 14 July 1990”. Este tipo de literal é um tipo de dado conhecido como date. Podemos também associar a expressão“ La Joconde à Washington” a um literal que representa um texto e seu tipo de dado é conhecido como string.
Reforçamos novamente aqui que uma das vantagens incorporadas com o IRI é a ampliação dos caracteres além da tabela ASCII. Ou seja, podemos então definir que “La Joconde à Washington” é um literal relacionado a um vídeo sobre a Monalisa descrito utilizando-se o idioma Francês (i.e. “fr”), enquanto ワシントンでモナリザ é um literal relacionado ao mesmo vídeo, porém utilizando o idioma Japonês (ex. “jp”). É importante frisar que os literais estão associados a tipos de dados. Como o RDF foi construído como uma camada acima do XML (vide Figura 1.7 ou Figura 1.8), todos os tipos de dados disponíveis em XML podem ser reusados em RDF. A lista de tipos de dados disponíveis em XML é apresentada na Figura 2.10. No RDF, um novo tipo de dado foi adicionado para descrever HTML, que é o rdf:HTML.
No entanto, não podemos esquecer que os literais só podem ser aplicados a objetos, ou seja, nunca podem descrever sujeitos ou predicados. Veremos em capítulos subsequentes que uma das recomendações para Dados Abertos Conectados é utilizar URIs para nomear as coisas (Berners-Lee, 2006) ao invés de aplicar Literais. Este tipo de visão é uma boa prática recomendada para Dados Abertos que estendeu a ideia de RDF, qualificando ainda mais os dados que estão sendo representados.

Como resultado do reuso de diversos vocabulários, bem como dos literais, temos como Grafo RDF resultante da Figura 2.9, o grafo apresentado na Figura 2.11. Observemos que em “La Joconde à Washington” foi reutilizado um recurso do catálogo de dados publicado pela Europeana 35, enquanto que o literal de data permaneceu. Além disso, o literal de data para representar a data de nascimento de Bob, apareceu após a data “^^xsd:date”. O delimitador “^^” caracteriza que estásendo descrito um literal, enquanto que o xsd é o alias (pseudônimo) criado que faz referê ncia ao XML Schema (vide Figura 2.4). Finalmente, “date” equivale ao tipo de dado que está sendo definido. Outro vocabulário reusado foi o Schema.org, que provêuma série de esquemas e tem sido usado por engines de buscas de empresas como Google, Microsoft, Yahoo! e outros.

1.4 Múltiplos Grafos
Outro conceito importante que foi adicionado à nova versão do RDF é o conceito de Múltiplos Grafos. Ao se criar um documento RDF, pode-se adicionar outros grafos que se conectam ao grafo original, proporcionando assim catálogos de dados (do Inglês Datasets) conectados. O mais importante é que os múltiplos grafos podem ser acessados por um único IRI.
Ao observarmos o exemplo da Figura 2.9, referente à pessoa Bob, podemos ver que pela Figura 2.11, todos os dados relacionados à Mona Lisa estão sendo reutilizados. Isto quer dizer que o Grafo da Mona Lisa poderia ser acessado de maneira independente por um único IRI, como o disponível em Wikidata, com o IRI https://www.wikidata.org/wiki/Special:EntityData/Q12418. Com isso, teríamos dois grafos conectados, sendo um para descrever Bob (http:// example.org/bob) e outro para Mona Lisa, como apresentado na Figura 2.12.

A partir do momento que podemos conectar 2 grafos RDF, podemos fazer a conexão de múltiplos grafos e termos a atribuição de um único IRI. Isso facilita a reutilização de grandes quantidades de dados presentes em grafos RDF sem a necessidade de um usuário ter o conhecimento completo dos mesmos. Além disso, facilita a extensão de grafos de maneira mais simples. Por exemplo, o grafo da Figura 2.12 poderia ser facilmente estendido e incrementado adicionando qual a licença aplicada aos dados de Bob e quem publicou os dados, como apresentado na Figura 2.13.

De acordo com as Figuras 2.12 e 2.13, podemos observar 3 grafos associados, sendo um que descreve a pessoa Bob, outro para descrever Mona Lisa, outro para informar a licença relacionada à pessoa Bob e quem publicou. O grafo base 36 equivale ao primeiro grafo que conecta com os grafos subsequentes, sendo neste caso <http://example.org/bob>. Desta forma, pelo IRI <http://example.org/bob>, podemos acessar os múltiplos grafos supracitados. O código resultante deste exemplo é apresentado na Figura 2.14 em TriG 37.


2.3.2 Esquema RDF (RDF-S)
Esta subseção tem por objetivo apresentar o esquema RDF que é uma extensão do RDF, conhecido como RDF Schema ou RDF-S, que possibilita descrição semântica. O RDF-S é um vocabulário para modelagem de dados que amplia a expressividade do RDF para prover mecanismos de descrição de taxonomias entre recursos e suas propriedades. Ou seja, o RDF-S permite descrever grupos de recursos (também conhecidos como classes) e suas relações utilizando o conceito de triplas apresentado na seção anterior. A Figura 2.15 apresenta os principais elementos do RDF-S. Apesar da Figura 2.15 ter sido extraída da especificação do RDF 1.0, que foi recomendação do W3C em Março de 2000 (Brickley, et al., 2000), os elementos descritos na Figura também estão presentes na versão .1 de Fevereiro de 2014 (Brickley, et al., 2014).

Da mesma forma que o XML Schema é baseado no XML, o mesmo ocorre com o RDF Schema, que é baseado no RDF. Isto implica que o RDF-S possui um IRI para cada recurso e que também possui uma estrutura de triplas <sujeito> <predicado> <objeto>. Gostaríamos de destacar dois conceitos básicos presentes em RDF-S:
• Classe: este conceito é utilizado para descrever recursos em um documento RDF. Quando temos interesse em descrever recursos, podemos simplesmente utilizar o rdfs:Resource, que é uma instância de rdfs:Class. Outros dois tipos de classes importantes são rdfs:Literal e rdfs:DateType para definir tipos primitivos e derivativos. Toda classe RDF possui um IRI associado e podemos definir propriedades para as classes RDF.
• Propriedade: o papel de uma propriedade é definir relações entre sujeitos e objetos. Um tipo de propriedade importante equivale ao rdf:type. Ao dizermos que uma <Classe A> é uma instância da <Classe B>, usamos o rdf:type. Ou seja, <Classe A> rdf:type <Classe B>. Por exemplo, na Figura 2.12 para indicar que Bob é do tipo Pessoa, do vocabulário FOAF, fazemos:
Bob rdf:type foaf:Person
Outros dois tipos de propriedades bastante usadas são rdfs:domain (responsável por indicar o sujeito da relação) e rdfs:range (responsável por indicar o objeto da relação). Quando dizemos <Propriedade P1> rdfs:domain <Classe C1>, quer dizer que o sujeito da relação é a classe C. O mesmo ocorre para indicar o objeto, como <Propriedade P2> rdfs:range <Classe C2>.Por exemplo, na Figura 2.12, onde temos a relação Bob foaf:knows Alice, estamos abstratamente dizendo que uma pessoa conhece outra pessoa. Neste caso, temos que a propriedade foaf:knows possui tanto o domínio (i.e. rdfs:domain) quanto a imagem (i.e. rdfs:range) como foaf:Person.
Ressaltamos a importância do RDF-S que é usado para representação e modelagem de conceitos. No próximo capítulo iremos tratar sobre modelagem utilizando os diversos conceitos já apresentados até o momento.
2.3.3 Os Formatos de Serialização em RDF 1.1
Até o momento abordamos características importantes do Modelo RDF, bem como conceitos fundamentais do RDF Schema, que determina a semântica por trás do Modelo RDF. Outro aspecto fundamental para RDF são as formas que eles podem ser apresentados ou serializados. Esta é de fato uma grande diferença presente no RDF 1.0 e em sua evolução para o RDF 1.1, pois o número de formatos de serialização foi bastante ampliado, como pode ser visto na Figura 2.16 (Wood, 2014) .

Apesar de termos abordado o RDFa e o Turtle em seções anteriores, nas próximas subseções iremos brevemente abordar cada um dos formatos de serialização.
3.1 RDFa
O RDFa (Resource Description Framework in Attributes) tem por objetivo embutir código RDF em estruturas HTML e XML (Herman, 2015).Isto é feito através da inclusão de significado via atributos dos elementos. É por esta razão que RDFa é considerada o RDF em Atributos. A grande vantagem de utilização do RDFa é que máquinas de buscas podem melhorar seus resultados aumentando a precisão sobre o real significado de determinado documento. Ou seja, as máquinas de buscas podem agregar os dados de um documento com dados de outro documento, enriquecendo assim os resultados de buscas. Na Figura 2.17 podemos ver um código HTML com atributos RDF embutidos que representa o grafo apresentado na Figura 2.12.


Podemos observar que no código HTML aparecem quatro atributos com o objetivo de descrever código RDF, sendo eles:
• prefix, que tem por objetivo descrever os vocabulários que estão sendo reusados no documento HTML. Neste caso, temos o reuso de três vocabulários bastante conhecidos por profissionais da área (FOAF, Schema.org e Dublin Core);
• resource, cujo objetivo é descrever um determinado recurso, da mesma forma que foi explicado no RDF Esquema, para a classe rdfs:Resource . Por exemplo, na linha 4 temos a descrição do recurso http://example.org/bob#me;
• property, cujo objetivo é descrever uma propriedade. Semelhante ao atributo resource, o atributo property é similar à propriedade rdf:Property. Como explicamos anteriormente (vide Subseção 1.3.2), uma propriedade tem o objetivo de relacionar dois elementos, ou seja relacionar um sujeito a um objeto. Isto quer dizer que uma propriedade irá relacionar dois recursos. Podemos observar que como consequência a isto, todas as propriedades apresentadas no código da Figura 2.17 aparecem dentro da estrutura de um elemento <div>. Isto quer dizer, por exemplo, que das linhas 4 a 13, há 3 triplas relacionadas à Bob
http://example.org/bob#me foaf:knows Alice
http://example.org/bob#me schema:birthDate 1990-07-04
http://example.org/bob#me foaf:topic_interest the Mona Lisa
• typeof, que equivale ao atributo para representar o elemento rdf:type (i.e. tem o mesmo objetivo do rdf:type). Por exemplo, na linha 04 temos
http://example.org/bob#me rdf:type foaf:Person
3.2 RDF/XML
RDF/XML (Gandon; Schreiber, 2014) foi a primeira serialização feita para RDF e pode ser claramente reconhecida pelo “bolo de noiva” (i.e. arquitetura em camadas) apresentado na Figura 1.7. Este formato possui uma sintaxe XML para os grafos RDF. A figura 2.18 apresenta o mesmo código RDFa, porém em RDF/XML.
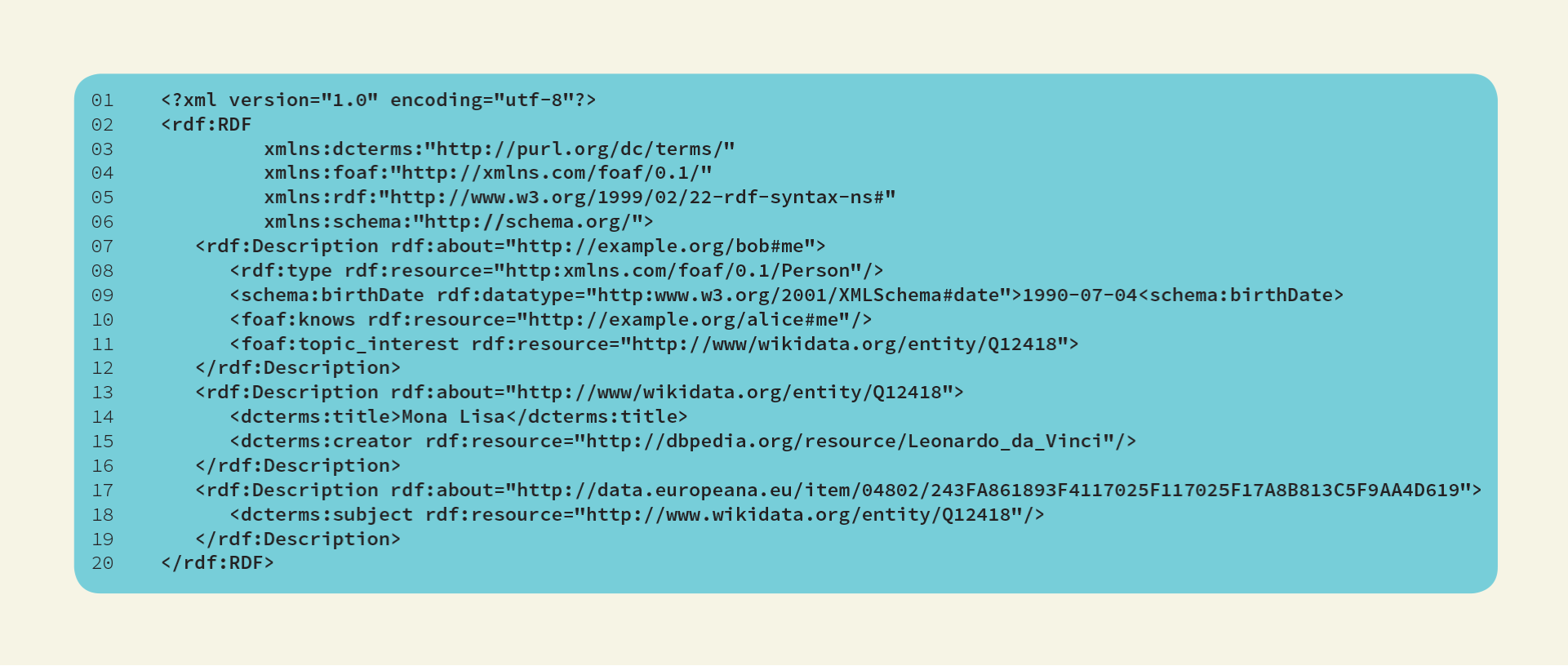

Podemos observar que a primeira linha do código da Figura 2.18 já apresenta o elemento <?xml>. Diferente do RDFa, que tem todo os seus elementos dentro da estrutura do HTML, o RDF/XML possui toda a sua estrutura dentro do XML e da tag <rdf:RDF>. Já o elemento rdf:Description é utilizado para identificar sujeitos. Ao observarmos o código da Figura 2.18, o primeiro sujeito apresentado (vide Linha 07) possui quatro sub-elementos. Isto quer dizer que cada sub-elemento apresentado entre as linhas 08 e 11 representam uma tripla combinada com o sujeito descrito na linha 07. Outra característica importante que apresentamos no RDF/XML é que o sujeito, apesar de ser identificado pelo elemento rdf:Description, é descrito pelo rdf:about.
Diferentemente do código em RDFa, os tipos de dados reusados do esquema XML foram explicitamente definidos para identificar a semântica do schema:birthDate.
3.3 JSON-LD
JSON-LD (Sporny, et al., 2014) é um dos mais recentes formatos de serialização e surgiu como uma extensão da proposta do JSON, com o objetivo de transformar código JSON para RDF com o mínimo de esforço possível. Este formato é bastante intuitivo para programadores já familiarizados com a sintaxe JSON. A Figura 2.19 apresenta um código em JSON-LD.

Podemos observar que o código da Figura 2.19 descreve o recurso Bob, identificado pelo IRI http://example.org/bob#me, através da chave @id, descrita na linha 03 e o tipo de recurso sendo descrito na linha 04. As linhas 05, 06 e 07 definem objetos que o sujeito Bob se relaciona. Da mesma forma que os outros formatos de serialização, podemos identificar as triplas no JSON-LD, como exemplificadas abaixo
http://example.org/bob#me birthDate 1990-07-04
http://example.org/bob#me knows http://example.org/alice#me
http://example.org/bob#me interest http://www.wikidata.org/entity/Q12418
Dois pontos que devemos destacar deste código JSON-LD é que
i) na linha 07 podemos identificar outro recurso no qual o sujeito Bob se relaciona, onde este recurso equivale a outro grafo, contendo uma estrutura própria e sendo identificado pelo IRI descrito na linha 08; e
ii) nãoé possível identificar o esquema e a semântica dos recursos. Isto acontece por que o contexto no qual os recursos estão inseridos ficam em outro documento. Este contexto é identificado pelo objeto @context, descrito na linha 02. Logo, o código que descreve o contexto é apresentado na Figura 2.20.
É através deste contexto que é possível fazer o mapeamento do código JSON-LD descrito na Figura 2.19 no grafo apresentado na Figura 2.12.
3.4 N-Triples
N-Triples faz parte da família de formatos Turtle. N-Triples é o formato de serialização mais simples e intuitivo que existe (Carothers, et al., 2014). Como a principal característica do RDF é possuir uma estrutura em triplas <sujeito> <predicado> <objeto>, N-Triples simplesmente estrutura o código em forma de triplas (vide Figura 2.21). Isto quer dizer que cada linha de um código N-Triples equivale a uma tripla. Por exemplo, o código da Figura 2.21 possui 07 linhas, representando assim 07 triplas.
Podemos ver que ao final de cada linha há um ponto (“.”), sendo usado exatamente para identificar o fim de uma linha. Outros aspectos a observarmos é que todos os IRIs são absolutos, ou seja, possui a identificação do recurso completo. Devido a sua simplicidade, não é possível definir prefixos e usar IRIs relativos 38.
3.5 Turtle
Com o objetivo de ampliar as possibilidades de descrição de um documento N-Triples, o formato Turtle foi criado, podendo assim descrever prefixos e IRIs relativos na estrutura do documento (Prud'hommeaux, et al., 2014). Da mesma forma que N-Triples, o formato Turtle é bastante simples e ainda mais fácil de ler. O có digo da Figura 2.22 apresenta a estrutura em Turtle.
As seis primeiras linhas do código mostram os IRIs que podem ser definidos como prefixos e IRI base do documento, característica esta não permitida no N-Triples. Podemos ainda observar que as linhas 08, 14 e 18 apresentam sujeitos com seus predicados e objetos logo abaixo deles. Este tipo de organização e endentação torna bastante intuitiva a leitura do documento, facilitando assim a identificação das triplas RDF.
Objetivando ainda mais a simplificação da leitura de documentos RDF, a linha 09 apresenta mais uma característica do formato Turtle. A primeira tripla descrita para Bob é bob#me a foaf:Person. O elemento que é responsável por relacionar o sujeito ao predicado deste exemplo é o token “a”. Este token “a” possui a mesma semântica da propriedade rdf:type e é usada para dizer que bob#me é do tipo foaf:Person. Você pode estar se perguntando por que o “a”. A letra “a” representa um artigo da língua inglesa, sendo traduzido para português como “um” ou “uma”. Ou seja, ao lermos a tripla descrita acima na linha inglesa seria Bob is a person (no português: Bob é uma pessoa). Logo, o token “a” foi adicionado para tornar o formato Turtle ainda mais intuitivo para o ser humano.
3.6 TriG
O formato TriG é uma extensão do formato Turtle, ou seja, herda a mesma simplicidade e facilidade de leitura (Carothers, et al., 2014). Este formato foi criado para representar múltiplos grafos, que foi adicionado a partir da especificação 1.1 do RDF. Um exemplo de código TriG para representação de múltiplos grafos foi apresentado na Figura 2.14.
Observemos que a única diferença entre o código Turtle e o código TriG é que os sujeitos descritos são encapsulados dentro de uma palavra-chave chamada GRAPH. Isto quer dizer que o conjunto de triplas dentro do elemento GRAPH representa um catálogo de dados (ou dataset). No código da Figura 2.14, são descritos três grafos, sendo dois grafos com a identificação (named graph) e um sem (aplicando blank nodes). Na estrutura da linguagem 39, é obrigatória a descrição de pelo menos dois grafos, sendo um necessariamente descrito como blank node, ou seja, sem IRI para identificar o grafo. É importante destacar que um documento Turtle também é considerado um documento TriG.
3.7 N-Quads
Finalmente, o formato N-Quads é utilizado para permitir o intercâmbio de catálogo de dados (Carothers, 2014). Como você pode ver no código da Figura 2.23, ele é uma extensão da N-Triples e possui em cada linha a identificação de uma tripla.
Na Tabela 2.3 apresentamos um resumo dos formatos de serialização, bem como a estrutura do código para cada formato e o propósito de uso de cada um deles.
TABELA 2.3
FORMATOS DE SERIALIZAÇÃO E SUAS CARACTERÍSTICAS E USO
| Serialização RDF | Tipo de Código | Quando usar |
|---|---|---|
| RDFa | Código RDF embutido em HTML | SEO |
| RDF/XML | Código RDF com estrutura em XML | Aplicações que usam estruturas em XML |
| JSON-LD | Código RDF com estrutura JSON | Aplicações que usam JSON |
| N-Triples | Código RDF com estrutura de Triplas | Processamento e intercâmbio de Big Data em RDF. |
| Turtle | Código RDF para facilitar a leitura humana | Processamento e intercâmbio de Big Data em RDF |
| TriG | Código com estrutura Turtle | Representação de Múltiplos grafos |
| N-Quads | Código RDF com estrutura de Triplas | Processamento e Intercâmbio de grandes catálogos de dados. |
2.4 Exemplos de Sucesso de Dados Conectados
Nesta seção, iremos apresentar 5 casos de sucesso de utilização de Dados Abertos Conectados, sendo 3 deles relacionados a aplicações empresariais e 2 com aplicações governamentais.
2.4.1 Tornando a Web de Dados Possível: DBPedia
Apesar deste exemplo ser mais um caso mais técnico, consideramos de fundamental importância dissertarmos sobre ele, dado o impacto da DBPedia na evolução da Web em direção a Web de Dados.
Este caso de sucesso é sem dúvida o responsável pela ampliação na força tarefa que estabeleceu as bases para o advento da Web de Dados. A DBPedia possui uma estrutura em RDF/OWL que equivale ao nó central da Web de Dados, como apresentamos na Figura 1.13. Foi por meio da comunidade de Web Semântica e da base de dados da DBPedia que a Web de Dados começou a virar uma realidade. Projeto iniciado em 2007 (The Linked Open Data Project), a DBPedia hoje possui atualmente mais de 30 milhões de recursos descritos, em 120 idiomas. Só na língua inglesa, descreve 832 mil pessoas, 639 mil lugares, 372 mil trabalhos criativos (i.e. músicas, filmes, jogos), 209 mil organizações, 226 mil espécies e 5.6 mil doenças. Na língua portuguesa, a DBPedia descreve 736 mil recursos, sendo uma das 12 línguas mais povoadas na ontologia da DBPedia. Além disso, DBPedia reusa recursos de quase 40 diferentes catálogos de dados e foi conectada através de mais de 40 milhões de links a uma centena de catálogos de dados (Lehmann, et al., 2014) .
A Figura 2.24 apresenta a arquitetura atual da DBPedia. Como podemos observar, a arquitetura dá suporte a três tipos de atores diferentes, sendo dois deles para consumo utilizando diretamente as tecnologias e padrões para Dados Conectados. Para cada tipo de usuário, faz-se uso de uma tecnologia diferente. Ou seja, usuários podem acessar via HTML, via RDF (por exemplo, Open Link Data Explorer 40) e via SPARQL Endpoint 41. Toda a comunicação cliente-servidor ocorre, pelo lado cliente através dos mecanismos supracitados, e do lado servidor através do servidor Virtuoso 42.
2.4.2 Consumindo Dados Eficientemente: BBC
Considerado um dos exemplos de Dados Conectados mais famoso, a BBC está na Web desde 1994 e vem trabalhando com enriquecimento de páginas web a mais de 10 anos, inicialmente com a programação de rádio e depois expandindo para TV, música, gastronomia, entre outros. Por volta de meia década, a BBC começou a publicar dados sobre as notícias de música, reusando o vocabulário da MusicBrainz 43. Atualmente, a BBC faz o reuso de diversos vocabulários e catálogo de dados.
A arquitetura de Dados Conectados da BBC pode ser vista na Figura 2.25. A BBC possui o seu conteúdo armazenado utilizando uma TipleStore (ex. OWLIM 44) e possuindo uma API para cada conteúdo com Dados Conectados.
A título de exemplo sobre o funcionamento da solução de Dados Abertos da BBC, apresentamos o caso a seguir. Ao entrarmos na página que oferece informações sobre o cantor do Pink Floyd, Roger Waters 45, podemos visualizar a página conforme mostra a Figura 2.26. Esta página é criada (semi-) automaticamente por meio do uso de dados abertos e tecnologias da Web Semântica, fazendo reuso do conteúdo tanto da Wikipedia (caso você abra a página do Roger Waters na Wikipedia, encontrará o mesmo conteúdo) quanto do MusicBranz. De acordo com a Figura 2.26, o retângulo vermelho indica o trecho recuperado automaticamente da Wikipedia e o retângulo verde, o trecho recuperado do MusicBranz.
Outro exemplo da própria BBC é a parte de programação da Rádio e TV. Esta parte faz uso de uma ontologia chamada Programme Ontology (Raimond, et al., 2009) e reusa diversas outras ontologias. Esta ontologia da BBC está disponível na Figura 2.27. Diferente da categoria de música, que só serializa em JSON e XML, a parte de programação da BBC serializa também em RDF 46.
2.4.3 Um Caso Brasileiro: Globo.com
A Globo.com é um caso brasileiro que está fazendo uso de ontologias não somente para a publicação de conteúdo, mas também para decidir que tipo de gadget é disponibilizado numa página de notícias. A Globo possui um grupo de profissionais da Web Semântica dedicado a organizar e distribuir todo o conteúdo produzido pelas organizações Globo. Atualmente a Globo.com possui uma ontologia de base que conecta e distribui dados de diferentes portais de informações da Globo (G1, Globo Esporte, Ego e TVG). Um exemplo é apresentado na Figura 2.28, onde a notícia sobre o Barcelona foi gerada com especificações de tags que apoiam na descrição semântica das páginas e, por consequência, os gadgets (por exemplo, na parte direita da página, em leia mais sobre) são gerados e conectados a outras notícias automaticamente (Medeiros, 2013). Observe que na Figura 2.28, tanto a notícia quanto os gadgets estão relacionados com o time de futebol Barcelona e não com a cidade espanhola de Barcelona. Isto é possível exatamente por causa da anotação semântica das notícias, que permite diferenciar que Barcelona está relacionado ao time de futebol e não necessariamente à cidade de Barcelona.
FIGURA 2.28
EXEMPLO DE USO DE SEMÂNTICA NO GLOBO ESPORTE
Isto é possível graças à definição de uma ontologia base para conectar as notícias publicadas em diferentes portais da globo e a nova arquitetura baseada em Dados Conectados que faz uso de uma API Restful, chamada Brainiak, como mostrada na Figura 2.29.
2.4.4 Governo Conectado: Data.gov.uk
O Portal de Dados do Governo Britânico é uma das grandes iniciativas governamentais de abertura de Dados Conectados. O data.gov.uk possui em sua base quase 19 mil catálogo de dados disponíveis e os mesmos são categorizados de diferentes formas para facilitar a busca e descoberta de catálogos. Uma das formas que o Portal disponibiliza é através do esquema de classificação de Dados Abertos das 5 Estrelas (vide Figura 2.2), de acordo com a Tabela 2.4.
TABELA 2.3
CLASSIFICAÇÃO DOS CATÁLOGOS DO PORTAL BRITÂNICO DE COM O ESQUEMA 5 ESTRELAS.
| Número de Estrelas | Quantidade de Catálogos |
|---|---|
| - | 13.965 |
| ★ | 281 |
| ★★ | 1.145 |
| ★★★ | 2.345 |
| ★★★★ | - |
| ★★★★★ | 168 |
Podemos observar que de acordo com a Tabela 2.3, ainda há muitos catálogos de dados para os quais não foi defina uma licença e não podem ser considerados abertos. Alguns destes catálogos possuem formatos de dados abertos, como XML e CSV, no entanto não definiram ainda uma licença.
Um exemplo de catálogo de dados com 5 estrelas é o Land Registry Price Paid Data (ou Dados dos Registros de Preços Pagos por Terra) sobre a Inglaterra e País de Gales. Através deste dataset, é possível ter acesso a uma série temporal disponível em diferentes formatos (inclusive RDF) sobre o preço de cada venda de terra nestas duas regiões.
Outro cenário possível é que a maioria dos catálogos com formatos RDF disponíveis é sobre organogramas, fornecendo informações dos profissionais de cada organização e nível hierárquico nesta mesma organização. Um tipo de aplicação, que pode ser construída utilizando-se dos dados dos diversos organogramas, é a que verifica acúmulo de cargos públicos e horas de trabalhos semanais.
2.4.5 Nova York Conectada pelo povo e para o povo
A cidade de Nova York possui uma proposta de abertura de Dados Conectados, integrada com a sociedade civil. A cidade não somente abre os dados do governo, como estimulam a sociedade a desenvolver aplicações utilizando estes dados, criando assim uma cidade conectada pelo povo e para o povo.
Uma das políticas do Portal de Dados Abertos da Cidade de Nova York é que os dados são abertos por padrão. No entanto, alguns dos dados que são considerados confidenciais não são publicados, de acordo com o relatório de Políticas de Segurança da Informação da Cidade de Nova York [http://www.nyc.gov/html/doitt/downloads/pdf/data_classification.pdf] A arquitetura lógica do Portal de Dados Abertos da Cidade de Nova é apresentada na Figura 2.30.
Observa-se que o Portal faz uso de uma camada de serviços de integração, tanto de dados geográficos, quanto de serviços de monitoramento. O Portal possui mais de 1000 catálogos de dados disponíveis em vários formatos, inclusive RDF. Por meio da plataforma utilizada, é possível tanto fazer a publicação dos dados abertos de forma simplificada e sistemática, quanto exportar os dados para diferentes formatos. Além disso, a plataforma disponibiliza uma API onde a sociedade civil pode consumir estes dados. É o que vem acontecendo através da iniciativa chamada BetaNYC 47, que possui mais de 1500 desenvolvedores cadastrados e é responsável por organizar Hackathons para promover o desenvolvimento de soluções utilizando Dados Conectados.
Como um exemplo deste tipo de iniciativa, citamos a WayCount, que é uma solução para Cidades Inteligentes. O objetivo do WayCount é prover um hardware que possa medir em tempo real dados sobre o tráfico de bicicletas e automóveis. Diferentes das soluções concorrentes, o WayCount possui dois princípios essenciais: baixo custo e dados abertos. Ou seja, através de uso de tecnologias de open source, o WayCount coleta dados em tempo real e disponibilizam como dados abertos, criando assim um rico repositório de dados abertos do tráfico para proporcionar a criação de cidades mais inteligentes.
Outro exemplo é o Data Explorer for US Politics (Explorador de Dados para a Política Americana), que é um plugin para o Chrome que disponibiliza dados sobre contribuições de campanhas. O Data Explorer está integrado à DBPedia, onde os dados são extraídos automaticamente (vide Figura 2.31).
2.5 Considerações Finais
O principal objetivo deste capítulo foi oferecer ao leitor uma visão geral sobre como a estruturação de dados é feita na Web e como esta estrutura pode ser utilizada para representar Dados Abertos Conectados. Este capítulo foi organizado por meio de exemplos visuais com o intuito de trazer para o leitor, pouco acostumado com o conceito de estruturação de dados na Web, uma perspectiva incremental de estruturação de dados abertos. Foi também intenção deste capítulo dissertar sobre o modelo RDF, apresentando suas características principais, a semântica por trás do RDF e as principais formas de serialização de documentos RDF. Por fim, foram apresentados casos de sucesso da utilização de Dados Conectados, sob as perspectivas acadêmicas, governamentais e empresariais.
Esperamos que as seguintes mensagens tenham sido passadas:
• Compreensão sobre estruturação de dados na Web de Documentos e na Web de Dados;
• Conhecimento sobre como estruturar dados segundo o esquema de 5 estrelas para abertura de dados;
• Entendimento sobre a importância do modelo RDF, bem como suas principais características;
• Aprendizado sobre alguns conceitos fundamentais para a semântica de documentos RDF;
• Compreensão sobre os diversos modelos de serialização de documentos RDF e suas aplicações;
• Visualização de casos de sucesso sendo aplicados nos contextos empresarial, governamental e acadêmico.