2. WWW e Semântica
Hoje em dia, para uma grande parcela da população mundial, a World Wide Web é algo tão presente quanto a televisão. A Web é um local onde as pessoas consultam informações, fazem compras, trabalham, conversam, estabelecem relacionamentos, etc. A Web é algo cotidiano, uma coisa óbvia. Qual a necessidade de explicar o que é a Web para uma criança de 10 anos nascida em uma grande metrópole? Para quem nasceu no século 21, a Web é a Web, assim como a luz é a luz. Apesar das enormes transformações efetuadas no modo de vida das pessoas, a partir da utilização da Web, ela ainda é muito recente, em constante e intensa transformação. Mas o que é a Web?
2.1 Web de Documentos
Em termos técnicos, a Web é um sistema que foi inventado por Tim Berners-Lee e Robert Cailliau [1] , em 1989, com o objetivo de utilizar a Internet para a consulta e a atualização de itens de informação (documentos) organizados em uma estrutura hipertextual. Hipertexto é um texto estruturado, composto por um conjunto interligado de itens de informação (nós) contendo, por exemplo, textos, imagens, vídeos, etc. A arquitetura desse sistema foi criada com base no conceito cliente-servidor, onde uma aplicação (um cliente Web) requisita um documento (um recurso) a uma outra aplicação (um servidor Web) informando a identificação desse documento.
Esse sistema é composto por três elementos básicos, definidos por meio de padrões internacionais:
• URL ( Uniform Resource Locator ) [2] é o identificador dos documentos, dos nós da estrutura. Por exemplo "http://pt.wikipedia.org/wiki/World_Wide_Web" identifica o documento que descreve a Web no site da Wikipedia em português.
• HTML ( Hypertext Markup Language ) [3] é a linguagem de marcação para a descrição dos documentos. Ela foi inicialmente projetada como uma linguagem para a descrição de documentos científicos, mas adaptações efetuadas ao longo do tempo permitiram que ela seja utilizada para descrever diversos outros tipos de documentos.
• HTTP ( Hypertext Transfer Protocol ) [4] é o protocolo de comunicação para acesso aos documentos. Esse protocolo estabelece as regras da comunicação entre duas aplicações, um cliente e um servidor, de forma a permitir a requisição de um conteúdo e o respectivo resultado retornado por essa requisição, por exemplo, uma página HTML.
O sistema funciona da seguinte maneira: uma aplicação-cliente, por exemplo, um navegador Web, requisita um documento ao servidor, identificando esse documento por meio de uma URL, e informando que esse documento deve ser preferencialmente descrito em HTML. Essa URL contém, também, a identificação do servidor que será responsável por gerenciar a requisição do documento. A comunicação entre o cliente e o servidor se estabelece por meio do protocolo HTTP. Uma vez feita a requisição de um documento pelo navegador, o servidor identificado pela URL devolve o documento desejado na forma de uma cadeia de caracteres formatada na linguagem HTML. Uma vez recebido o documento em HTML, o navegador é responsável por interpretar o código HTML e exibir as informações na tela. A ideia original desse sistema era a de que além de visualizar as informações contidas em um determinado documento, o usuário também pudesse alterar as informações desses documentos, algo semelhante ao que ocorre hoje em sites como a Wikipedia.
Além desses três elementos, um outro elemento importante nesse sistema é o link que pode ser estabelecido entre os diversos documentos, um hyperlink em um hipertexto. Os links fazem a interligação entre os diversos nós da estrutura. Um link pode ser incluído dentro do código de uma determinada página, utilizando um tag específico da linguagem HTML (o tag <a href=” url-do-link ”>), onde é possível especificar uma URL que aponta para um outro documento. Dessa forma temos uma rede, uma teia, uma Web de documentos interligados, um hipertexto. O documento, quando visualizado pelas pessoas em um navegador, é referenciado como sendo uma página da Web.
Resumindo, cada documento da Web pode ser acessado por meio de uma URL, podendo esse documento estar interligado a outros documentos por meio de links : um conjunto de documentos interligados por links . Essa é a Web de documentos.
O conteúdo de uma página exibida por um navegador pode conter diversas informações diferentes que serão utilizadas pelas pessoas. Podemos ter uma página, por exemplo, com informações sobre diversos produtos em promoção de uma determinada loja que vende produtos eletrodomésticos. Essas informações são descritas de forma a ser entendidas por seres humanos. O que em uma página Web é entendido por máquinas?
O navegador, ou outras aplicações que são executadas na Internet, não conseguem identificar o que está descrito nessas páginas da mesma forma que as pessoas conseguem entender. O navegador não entende o significado do texto contido nas páginas. O que um navegador consegue entender é a semântica da linguagem HTML, que contém formas de indicar, por exemplo, que uma determinada frase é um título, um tag específico da linguagem HTML, o tag <h1>, por exemplo. Portanto, podemos dizer que uma determinada frase, "A Web de Documentos", é um título: “<h1>A Web de Documentos</h1>”. O que o navegador consegue entender é a relação entre o texto "A Web de Documentos" e o tag <h1>, e a partir daí ter uma forma de exibir esse título dentro de um determinado estilo. Para o navegador é indiferente qual é o texto contido entre os tags <h1> e </h1>. Ele não entende o texto. Pode ser qualquer texto. O navegador não extrai nenhuma informação do texto em si.
2.2 Web Programável
O ambiente inicial da Web era composto, basicamente, por um universo de documentos estáticos mantidos em arquivos nos servidores Web, que eram requisitados pelos navegadores para ser exibidos aos usuários. Apesar de uma URL poder simplesmente apontar para um arquivo, também é possível que um servidor Web faça algo além de identificar o arquivo e enviá-lo de volta ao cliente. Ele pode executar um código de programa e, a partir dessa computação, retornar um conteúdo gerado dinamicamente por esse programa. Nesse caso, a página HTML retornada pelo servidor é a saída do programa executado a partir da requisição identificada pela URL.
Cada servidor Web executa um software específico para atendimento às requisições HTTP. Geralmente, um servidor HTTP tem um diretório, uma pasta, que é designada como uma coleção de documentos, arquivos que podem ser enviados em resposta às requisições dos navegadores. Esses arquivos são identificados a partir das URLs associadas às requisições.
Common Gateway Interface (CGI) é um método padrão usado para gerar conteúdo dinâmico em páginas e aplicativos da Web. Ele fornece uma interface entre o servidor Web e programas que geram o conteúdo dinâmico da Web. Esses programas são geralmente escritos em uma linguagem de script , mas podem ser escritos em qualquer linguagem de programação.
A Web evoluiu de um espaço simples para a exibição de páginas contidas em documentos estáticos, para um espaço onde diversos tipos de aplicações utilizam os navegadores como plataformas para a execução de programas. Hoje em dia, é possível fazer compras, executar procedimentos bancários, enviar mensagens, e uma infinidade de outras aplicações, a partir da utilização dos navegadores. Diversos ambientes de programação surgiram com o intuito de facilitar a criação e a execução dessas aplicações, como, por exemplo, ASP, ASP.NET, JSPJava , PHP, Perl, Python , Ruby on Rails , etc.
Aplicações são geralmente estruturadas em blocos lógicos chamados de camadas, onde para cada camada é atribuído um papel. A estrutura mais comum nas aplicações Web é a de três camadas: apresentação, lógica de negócios e armazenamento. Um navegador da Web é a primeira camada (apresentação). Um motor, usando alguma tecnologia de conteúdo dinâmico da Web (JSPJava, Python , etc.), é a camada intermediária (lógica de negócios). Um banco de dados é o terceiro nível (armazenamento). O navegador envia solicitações para a camada intermediária, que executa os serviços fazendo consultas e atualizações no banco de dados, gerando, então, a resposta na forma de uma interface de usuário.
A disseminação das aplicações Web demandou a necessidade de comunicação entre aplicações, de forma a possibilitar a troca de dados e serviços, o que fez surgir a ideia de Web Services e Web APIs , como implementações do conceito de componentes de software no ambiente Web. Web Services fornecem uma forma padrão de interoperação entre aplicações de software diferentes. É um sistema de software projetado para suportar interações máquina-máquina interoperáveis através de uma rede. Ele tem uma interface descrita em um formato processável por máquina (WSDL). Outros sistemas interagem com o Web Service usando mensagens descritas na sua interface, usando um protocolo específico (SOAP). Web APIs têm uma definição menos restritiva em relação à formatação dos dados na comunicação entre as aplicações, e utilizam um outro protocolo de comunicação (REST).
A ideia geral dessas duas tecnologias é possibilitar que aplicações possam fornecer serviços a ser consumidos por outras aplicações, o que resulta numa outra camada dentro do ambiente da Web. Nessa camada existe um tráfego de dados sendo trocados por aplicações, que podem ser manipulados, combinados e transformados, dependendo das tarefas ofertadas por cada aplicação Web, para, então, ser apresentados aos usuários.
Como forma de ilustrar a ideia de componentes, podemos pegar o exemplo de uma loja que faz vendas pela Internet e que precisa informar ao usuário qual o valor do frete dos produtos comprados. Em geral, o frete é feito por uma empresa terceirizada. Para que o site de vendas possa informar esse valor, a aplicação do site pode obter esses dados a partir de um serviço ( Web Service ou Web API ) oferecido pela empresa que fará o frete, e exibir esse valor na interface apresentada ao usuário. Esse tráfego de dados, entre a aplicação do site de vendas e o serviço Web oferecido pela empresa de frete, é invisível para o comprador dos produtos. O comprador só percebe a comunicação entre ele e o próprio site de vendas.
Um dos problemas que se apresentam nessa arquitetura de componentes Web é a de que o significado e o formato dos dados não seguem nenhum padrão, e são especificados por cada um dos serviços da forma que estes acharem mais conveniente. Dessa forma, uma aplicação que queira combinar dados de diversos componentes precisa saber cada uma das definições, e, no caso de querer fazer alguma integração desses dados, saber como interpretar as diferentes definições, de forma a identificar as semelhanças e as diferenças entre os diversos dados retornados pelos múltiplos componentes. Para cada novo serviço que se queira utilizar, é preciso entender a sua semântica e a forma como ela é descrita. A interoperabilidade semântica de diferentes serviços e seus dados tem que ser realizada de forma manual. O site do jornal The New York Times oferece um conjunto de mais de 10 diferentes APIs [5] para acesso a seus dados, cada uma com sua própria especificação e formato de dados. O site ProgrammableWeb [6] contém um catálogo com milhares de aplicações disponíveis com especificações das mais variadas e heterogêneas, e ilustra bem a diversidade existente no mundo da Web Programável.
2.3 Web de Dados
Páginas da Web, exibidas por um navegador, contêm um conjunto de informações que são consumidas por pessoas. São textos, fotos, vídeos, etc., dispostos na página, de forma que uma pessoa possa extrair um significado dessas informações. Essas informações agrupam, em geral, um conjunto de dados que têm algum relacionamento entre si e que, por algum motivo, faz sentido apresentá-los em uma única página, um documento único. A partir da requisição de uma URL, o servidor Web identifica quais os dados serão retornados para o navegador.
Em uma apresentação de Tim Berners-Lee [7] no “Open, Linked Data for a Global Community” , ele usa um pacote de salgadinhos como exemplo da diversidade de informações que existe na embalagem de um produto: fatos nutricionais, composição química, selos de qualidade, identificação por código de barras, formas de contato com a empresa fabricante, etc. Essas informações são descritas em vocabulários específicos que demandam um conhecimento prévio para o seu entendimento. Por exemplo, é preciso saber ler uma tabela de fatos nutricionais, entender que a tabela é referente a uma porção definida e que são listados percentuais relativos às necessidades diárias ideais para o consumo humano. Nessa embalagem, existem diversos dados diferentes agrupados em um único documento. Na realidade, podem existir muito mais informações disponíveis relativas a esse produto, mas por uma decisão que envolve diversos critérios, que podem incluir espaço disponível na embalagem, grau de importância da informação, etc., apenas algumas informações são listadas na embalagem. Muitas vezes, existe um endereço da Web impresso na embalagem que aponta para um local onde podem ser obtidas informações adicionais.
Considerando um exemplo da Web, em uma página de uma loja de vendas podem ser exibidas informações de diversos produtos diferentes, o endereço físico da loja, um telefone de atendimento ao cliente, etc. Todos esses dados são expostos em um único documento que é apresentado ao usuário, utilizando textos e recursos gráficos (cor, tipo e tamanho de letra, etc.) em uma disposição espacial dentro da página, de forma a comunicar as informações ao usuário. É um processo de comunicação. Um processo que entende que o receptor dessa mensagem é um ser humano. Como vimos anteriormente, o modelo inicial da Web entende essa rede como um conjunto de documentos interligados em uma estrutura de hipertexto. Quando é feita uma requisição a um servidor Web, este identifica qual o conjunto de dados que serão agrupados em uma determinada página. O acesso direto aos dados de forma individual não é permitido.
E se ao invés de considerarmos esses documentos como blocos estanques de dados, pensássemos em uma Web que pudesse permitir o acesso individual a todos os dados que são agrupados nessas páginas e, além dessa Web de Documentos, pudéssemos ter acesso a uma Web de Dados, onde cada um dos nós da Web não fosse mais, necessariamente, um documento, mas um determinado dado específico, um determinado recurso. Dessa forma, teríamos acesso a uma camada de granularidade mais fina da Web, e diferentes desenvolvedores poderiam criar aplicações que agrupassem esses dados de diferentes formas. No caso do exemplo do pacote de salgadinhos, uma determinada aplicação poderia listar um outro conjunto de dados relacionados ao produto sob uma perspectiva que achasse mais conveniente, de acordo com um outro critério, por exemplo, quanto a uma alimentação para hipertensos.
Máquinas de busca são uma das aplicações mais populares da Web. A Google se transformou em uma das maiores empresas do planeta a partir da necessidade de conectar os dados publicados com os possíveis consumidores desses dados: um intermediário no processo de comunicação. Para prover esse trabalho, as páginas da Web são varridas e analisadas por robôs para que a Google possa montar um banco de dados que consiga responder à procura requisitada por uma pessoa, da forma mais precisa possível. Os motores de busca têm uma compreensão limitada do que está sendo discutido nessas páginas Web. Considerando que existem diversos dados distribuídos em cada página, são necessários algoritmos que tentam extrair esses dados a partir de uma informação formatada para seres humanos. Como identificar todos esses dados sem uma indicação específica que possa ser entendida por máquinas? Como formatar informações que possam ser úteis para que máquinas entendam o significado das informações contidas em uma página Web? Como criar novas formas de distribuição desses dados?
As seções a seguir esclarecem as noções de semântica e metadados que são utilizadas para se alcançar a ideia de uma Web de Dados entendida por seres humanos e por máquinas.
2.4 Semântica
Neste guia estamos interessados em esclarecer a ideia de definir uma camada semântica ao modelo inicial da Web de Documentos. Como vimos anteriormente, a ideia inicial da Web foi a de servir como uma forma de navegação entre documentos dispostos em uma estrutura de hipertexto. Esses documentos são exibidos aos usuários por aplicações que interpretam a linguagem HTML. O conteúdo das páginas é visto pelas máquinas de uma forma apenas sintática. A interpretação da informação, propriamente dita, é feita pelas pessoas que visualizam as páginas. Qual a semântica das informações exibidas? Qual é o significado dessas informações?
Semântica, em linguística, é o estudo do significado que é utilizado para entender a expressão humana por meio da linguagem. Nós conseguimos entender o significado, por exemplo, desta frase, entendendo o significado de cada uma das palavras e as relações entre essas palavras dentro da frase. Entendemos, também, os sinais de pontuação como a vírgula, o ponto, etc., e a função deles no texto. Além disso, podemos entender imagens e códigos de cores e uma diversidade de signos codificados de diferentes formas. Uma informação pode, por exemplo, ser exibida em caracteres grandes e na cor vermelha, para indicar a necessidade de atenção com aquele texto. Tudo isso depende de diversos fatores, incluindo a cultura da pessoa que recebe a informação. O vermelho, por exemplo, tem significado diferente em culturas asiáticas.
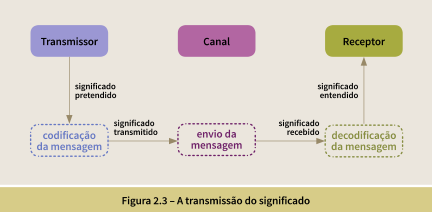
Modelos de comunicação são modelos conceituais utilizados para explicar o processo de comunicação humana ( figura 2.1 ). O primeiro modelo importante para a comunicação veio em 1949 e foi concebido por Claude Shannon e Warren Weaver, dos Laboratórios Bell. A comunicação é o processo de transferência de informações de uma parte (transmissor) para outra (receptor). O modelo inicial de Shannon e Weaver consistia de três partes principais: transmissor, canal e receptor. Em um modelo simples, a informação (por exemplo, uma mensagem em linguagem natural) é enviada de alguma forma (como língua falada) a partir de um transmissor/remetente/codificador para um receptor/destinatário/decodificador, por meio de um canal . Essa concepção de comunicação comum vê a comunicação como um meio de enviar e receber informações.

As figuras 2.2 e 2.3 ilustram como uma informação embutida dentro de um modelo mental de uma pessoa é codificada para depois ser transmitida por meio de um canal e, então, ser decodificada e mapeada para o modelo mental de uma outra pessoa.
Neste guia estamos tratando da introdução de semântica para máquinas que acessam as informações. Como uma máquina pode interpretar o conteúdo de uma página Web? Como fazer para codificar uma informação de forma a fazer o mapeamento correto entre o significado pretendido e o significado entendido?

Tomemos o exemplo dos sites de comparação de preços. Assim que surgiram os sites de venda na Web, que anunciavam um conjunto de produtos em suas páginas, com informações que incluíam a descrição do produto, imagens, preço, etc., surgiu a ideia da construção de sites que pudessem apresentar ao usuário a comparação de preços de um mesmo produto, ofertado em diferentes sites de vendas . Sites de comparação de preços podem ser considerados os primeiros exemplos de Web Semântica, mas os primeiros sistemas desenvolvidos nesses sites utilizavam softwares específicos ( scrapers ) para extrair informações estruturadas sobre os produtos a partir de páginas da Web. A informação é extraída a partir da identificação de padrões sintáticos dentro das páginas HTML.
HTML é uma linguagem de marcação de texto que define, basicamente, a estrutura de um texto. Em conjunto com uma outra linguagem (CSS), que define o estilo do texto, o navegador combina a estrutura e o estilo, e exibe as informações para as pessoas. Para que um scraper entenda o significado de um texto, é preciso procurar padrões que de alguma forma indiquem um significado. Vejamos um exemplo de um site de compras brasileiro, onde podemos identificar um padrão <tipo-preço>: uma cadeia de caracteres da forma “xxx,xx” ao lado dos caracteres “R$”. Não existe dentro da linguagem HTML um tag que indique explicitamente que essa cadeia de caracteres seja um preço. Nós humanos reconhecemos facilmente que essa informação é um preço. Num exemplo um pouco mais sofisticado, podemos ter o seguinte texto “Google Chromecast HDMI Streaming De: R$ 249,00 Por: R$ 192,72”, ao lado de uma imagem. Podemos escrever um código que procure pelas palavras “De” e “Por”, próximas de números que podem ser identificados no padrão <tipo-preço>, e entender que é uma promoção de produto. Definimos dessa forma um padrão <tipo-promoção>. E assim por diante. É fácil perceber que mudanças na disposição e no agrupamento das informações podem requerer uma reprogramação do scraper . A construção de um scraper requer extensa programação e é um sistema bastante instável, uma vez que pode haver a necessidade de reprogramação toda vez que uma loja online muda a estrutura de suas informações.
Como vimos na seção 2.3 (Web de Dados), a ideia é que possamos identificar de forma individual, legível por máquinas, cada um dos dados agrupados nas páginas Web. Para isso é necessário que coloquemos informações extras sobre esses dados, dentro do código HTML, informações que serão consumidas por máquinas. Essas informações sobre os dados são chamadas de metadados.
2.5 Metadados
Metadados são dados sobre dados. Eles fornecem informações adicionais sobre os dados, para ajudar desenvolvedores de aplicações e usuários finais a entender melhor o significado dos dados publicados, o seu conteúdo, a sua estrutura. Metadados são também utilizados para esclarecer outras questões relacionadas ao conjunto de dados como, por exemplo, a licença de uso, a empresa/organização que gerou os dados, a qualidade dos dados, a proveniência, como fazer o acesso, a frequência de atualização do conjunto de informações, etc. Os metadados têm como objetivo ajudar o processo de comunicação entre os publicadores e os consumidores de dados, para que os consumidores entendam todas as questões pertinentes para a utilização desses dados.
Metadados podem ser utilizados para auxiliar tarefas como, por exemplo, a descoberta e a reutilização do conjunto de dados, e podem ser atribuídos de acordo com diferentes granularidades, que vão desde uma única propriedade de um recurso (uma coluna de uma tabela) a um conjunto de dados completo, ou todos os conjuntos de dados de uma determinada empresa/organização. Um exemplo bem simples de metadados, de uso bastante corriqueiro, são os nomes das colunas de uma tabela colocadas na primeira linha de um arquivo em formato CSV. A função desses metadados é permitir que um leitor dos dados desse arquivo CSV entenda o significado de cada um dos campos, dos dados, de cada linha.
Até os dias de hoje, a Web se desenvolveu mais rapidamente como um meio de transmissão de documentos para as pessoas, ao invés de dados e informações que possam ser processados automaticamente. Metadados devem estar disponíveis em formas legíveis tanto para seres humanos quanto para máquinas. É importante proporcionar ambas as formas de metadados, a fim de alcançar os seres humanos e as aplicações. No caso de metadados legíveis por máquinas, a utilização de vocabulários de referência deve ser incentivada, como uma forma de reforçar uma semântica comum.
No exemplo da tabela CSV, é possível perceber a dificuldade que pode ocorrer quando não se utiliza um vocabulário comum de referência para descrever um metadado. Cada organização, cada pessoa, pode utilizar um termo diferente para designar o nome das colunas de uma tabela, que pode ser entendido dentro de uma determinada empresa, mas pode ter um significado ambíguo para pessoas diferentes em empresas diferentes, e, muitas vezes, dentro de uma mesma empresa. Alguns vocabulários de referência, de uso mais popular, são apresentados no capítulo 6. Por exemplo, os dados poderiam ter a sua proveniência descrita usando PROV-O , uma recomendação W3C que fornece um conjunto de classes, propriedades e restrições que podem ser usadas para representar e trocar informações de procedência geradas em sistemas diferentes e sob diferentes contextos.
Metadados podem ser de diferentes tipos. Esses tipos podem ser classificados em diferentes taxonomias, agrupados por diferentes critérios. Por exemplo, uma taxonomia específica poderia definir metadados segundo características descritivas, estruturais e administrativas. Metadados descritivos servem para identificar um conjunto de dados, metadados estruturais servem para entender o formato em que o conjunto de dados é distribuído e metadados administrativos servem para fornecer informações sobre versão, frequência de atualização, etc. Uma outra taxonomia poderia definir tipos de metadados com um esquema que considerasse as tarefas em que os metadados são utilizados, por exemplo, a descoberta e a reutilização de dados.
Metadados podem estar embutidos em páginas Web, mesclados (dentro do código HTML) com as informações a ser apresentadas aos usuários. Dessa forma, parte do código HTML é direcionada ao consumo humano e outra parte é direcionada ao consumo por máquinas. A seção 4.5 apresenta tecnologias utilizadas para embutir metadados em páginas Web. Além disso, metadados podem estar armazenados em catálogos que mantêm informações de dados publicados na Web. Os metadados podem também ser consumidos a partir de implementações que utilizam as tecnologias ligadas a Web Semântica e a Dados Conectados, apresentados nos capítulos 4 e 5.
Uma das primeiras formas de se incluir metadados em uma página Web foi por meio da utilização do tag <meta> da linguagem HTML. Esse tag têm dois atributos onde é possível se definir um nome e um conteúdo. Um dos primeiros usos do tag <meta> foi como forma de comunicação entre os publicadores das páginas e os robôs das máquinas de busca que fazem a varredura dessas páginas. Esses robôs leem as páginas com o intuito de gerar um índice que sirva de base para as respostas às requisições de busca dos usuários. Uma das diversas informações que o tag <meta> pode comunicar aos robôs é se uma página deve ou não ser incluída nos índices das máquinas de busca. Dessa forma é possível que um publicador possa informar aos robôs que não deseja aparecer em resultados de busca:
<meta name="robots" content="noindex" />
Um outro uso muito intenso do tag <meta> foi feito para que as máquinas de busca tivessem uma forma de indexar as páginas segundo um conjunto de palavras-chave definidas pelo publicador. Por exemplo:
<meta name="keywords" content="guia, web semântica" />
Como humanos, e entendedores da língua inglesa, podemos intuir que existe um conjunto de palavras-chave associadas à página onde esse tag foi incluído. Porém, a semântica do tag <meta> não define nenhuma interpretação específica para os atributos “ name” e “ content” . Essas informações são interpretadas pelas aplicações que leem as páginas de acordo com uma semântica que se estabeleceu com o uso. No caso do exemplo, um tag <meta> com ‘ name =” keywords ”’ é interpretado pelos robôs das máquinas de busca indicando que o campo “ content” terá uma lista de palavras-chave que serão associadas ao conteúdo da página. Para que essas convenções, como a de que “ keywords” significa um conjunto de palavras-chave, é necessário que sejam utilizados vocabulários de referência que tenham o seu significado compreendido pelo publicador, de forma que a aplicação que consome a página possa ter o significado entendido igual ao significado pretendido.
Essa forma de incluir metadados tem uma expressividade bastante limitada e vem sendo estendida a partir da criação de padrões para a definição de metadados e por um conjunto de vocabulários de referência, que são descritos nas próximas seções desse guia.