5. Linked Data
In the previous chapters of this guide we have seen the evolution of the Web of Documents and the Web of Data, and the technologies involved in adding semantics to help applications manipulate this information. The desired end result is a global database where a growing body of information can be accessed by a diversified set of applications with a broad range of purposes.
Data is published on the Web by various people and stored in various repositories around the world. To facilitate the construction of this global database, it is necessary to establish a standard way to link this data. This chapter will introduce the principles of what is called Linked Data. The application of this concept is expanding rapidly and its evolution is often illustrated by the figure of a cloud, the LOD cloud (Linked Open Data) [43], which shows a set of nodes representing sets of open data and links representing the connections established between these datasets. Figures 5.1 and 5.2 show the cloud in 2007 and 2014.

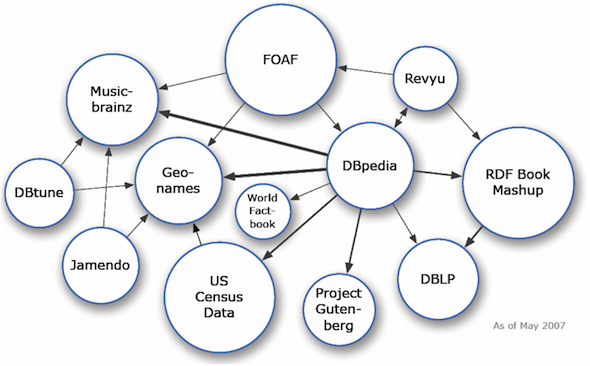{kind=link}

It is easy to see the tremendous expansion of the cloud and the importance of the DBpedia dataset (central node of Cloud 2014, with the largest number of links), which contains data represented in RDF on information contained in the info boxes of articles from Wikipedia.
5.1 The Four Principles
The idea of adding semantics to data is not enough to create a global database. To achieve this, the data needs to be linked. In 2006, Tim Berners-Lee defined a list of 4 principles[44] for linking this data:
• Use URIs as names for things (resources).
• Use HTTP URIs so that people can look up those things on the Web.
• When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL).
• Include links to other URIs, so that they can discover more things.
As we saw earlier, URIs are used to identify resources that can represent any concrete or abstract thing. The RDF model establishes a way to represent knowledge through triples that can define literal values for properties, or also establish relations between different resources, different things.
Using HTTP URIs enables this identification to be used for a request via the Web. The third principle establishes that once a request is made using one of these URIs (dereferencing), the server responsible for servicing this request should return some type of information related to the resource identified by the URI. As we saw in the section that introduces the concepts of SPARQL, the return of such a request could be something like the DESCRIBE command, where the triples are returned and the resource identified by the URI may appear as a subject, predicate or object. A simpler way would be to have a static RDF file with the triples deemed useful. This principle does not establish what should be returned. This decision belongs to the web server that services the request.
The fourth and final principle establishes the actual link between the data. It establishes that, whenever possible, a dataset should make reference to other sets, to permit navigation between the different nodes of the cloud. For example, the DBpedia website contains information about resources representing people, countries, etc. If another set of resources, for example, the BBC Music website, wants to refer to information about the artists that appear on its program schedules, it could include links between its resources and DBpedia resources. In other words, the triples contained in the BBC Music dataset will make reference to URIs of resources contained in the DBpedia triples.
5.2 The 5 Stars
The Web of Data is currently a heterogeneous space where various types of information are published in a wide variety of formats and storage structures. Data is stored in files in different formats, in databases and returned in web pages, web services and web APIs, in triple banks or SPARQL endpoints, etc.
As a way of guiding the publication of open data on the Web, in this new semantic vision, Tim Berners-Lee suggested a 5-star deployment scheme [45], to guide evolution in the direction of this Linked Data universe, a Web of Data where all information would be linked according to the four principles.
This scale consists of 5 levels:
1. Make your information available on the Web (in whatever the format) under an open license.
2. Make this information available as structured data (e.g., an Excel spreadsheet instead of an image scan of a table).
3. Use non-proprietary formats (e.g., a CSV table instead of an Excel spreadsheet).
4. Use URIs to denote things, so that people can point at your information.
5. Link your data to other data to provide a larger context for the information.
Each of these levels has costs and benefits, including simplicity of the procedure, data conversions, training of qualified personnel, etc., all in the interest of moving toward a dataset that is better described semantically and linked with other data. Following is an example of how the same dataset can be published within each of the 5-star classification levels.
Figure 5.3 shows an example of a 1-star publication: an image of a table published in a pdf file. This information can be easily processed by humans, but is very difficult for an application to understand.
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
Figure 5.4 shows the same information published in a spreadsheet of an Excel file, which would facilitate the processing of that information by applications, but still using a proprietary format. This is an example of a 2-star publication.
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
Figure 5.5 presents the same information published in a file in CSV format (a non-proprietary format). This is an instance of a 3-star publication.
Day,Lowest Temperature (C)
"Saturday, 13 November 2010",2
"Sunday, 14 November 2010",4
"Monday, 15 November 2010",7
The 4-star classification is a publication level that moves into a stage belonging to the Semantic Web. In the example used, the elements of the cells could be associated with the properties of certain vocabularies. Figure 5.6 shows how a Web page [46] could be viewed by users, with the weather forecast information arranged in a table.

Figure 5.7 shows an excerpt of the HTML code with RDFa insertions included as a way of adding semantic information to the data. One of the vocabularies used is the meteo vocabulary [47], which defines a set of properties for weather events.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<table border="1px">
<tr>
<th>Day</th>
<th>Lowest Temperature (°C)</th>
</tr>
<tr rel="meteo:forecast" resource="#forecast20101113">
<td>
<div about="#forecast20101113">
<span property="meteo:predicted"
content="2010-11-13T00
datatype="xsd:dateTime">Saturday, 13 November 2010
</span>
</div>
</td>
<td rel="meteo:temperature">
<div about="#temp20101113">
<span property="meteo:celsius"
datatype="xsd:decimal">2</span>
</div>
</td>
</tr>
...
Figure 5.8 presents the triples extracted from the page, which can also be viewed using the RDF browser Graphite [48].
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix meteo: <http://purl.org/ns/meteo>
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
rdf:type meteo:Place ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 .
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
A 5-star classification denotes the inclusion of information in the Linked Data universe. In the case of the example used, a link was made between data published on the page and data published about the city of Galway in DBpedia, using the property "owl: sameAs", which indicates that the two URIs represent the same thing. It also created a new feature ("#temp"), which makes a link between "temperature" and information contained in DBpedia.
Figures 5.9 and 5.10 show the new insertions, in relation to the 4-star example.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Galway">
</span>
<table border="1px">
<tr>
<th>Day</th>
<th>
<div about="#temp">Lowest
<a rel="rdfs:seeAlso"
href="http://en.wikipedia.org/wiki/Temperature"
resource="http://dbpedia.org/resource/Temperature">
Temperature
</a>
(<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Celsius">
°C</span>)
</div>
</th>
</tr>
...
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix dbp: <http:/dbpedia.org/resource/> .
@prefix meteo: <ttp://purl.org/ns/meteo> .
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
df:type meteo:Place ;
owl:sameAs dbp:Galway ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 ;
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp
owl:sameAs dbr:Celsius ;
rdfs:seeAlso dbr:Temperature .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
5.3 Linked Data API
One of the four principles of Linked Data states that when the URI of a resource, such as a school, is accessed, information relevant to the identified resource will be returned (dereferencing). This information can be stored, for example, in static files containing the set of triples that the web server understands as being relevant information about the resource. However, this information is often built dynamically from queries to a SPARQL endpoint. This implies that users of SPARQL queries have an understanding of the data scheme and vocabularies used, which are not always easy to understand.
The intent of Linked Data API (LD API) [49] is to provide an easy way to access Linked Data via the Web, enabling sets of resources to be displayed as URIs that are easy to query and can be filtered, paged and sorted, using relatively simple query parameters. LD API supports multiple result formats, including JSON, XML, RDF/XML and Turtle.
LD API is a specification for a middle layer of software that relies on a SPARQL endpoint and provides a Web API to access data. The mapping is configured by the data server administrator and complies with nomenclature standards, such as: http://orcamento.dados.gov.br/doc/{ano}/ItemDespesa, where {ano} (i.e., year) may be replaced with a specific year in order to obtain specific results for certain data: http://orcamento.dados.gov.br/doc/2013/ItemDespesa. Figure 5.11 shows the query that would be necessary to obtain the triples related to this information.
PREFIX loa: http://vocab.e.gov.br/2013/09/loa#>
SELECT ?item
WHERE {
?item loa:temExercicio [loa:identificador 2013]. } OFFSET 0 LIMIT 6
Thus, patterns can be specified that accept, as parameters, information defined in the URI for access to resources. For example, the website that permits access to data from the Brazilian federal budget [50] accepts the URI patterns presented in Figure 5.12.
LD API is an open source specification and there are several products that implement it, including Elda [51] from Epimorphics.
/doc/{ano}/Acao
/doc/{ano}/Acao/{codigo}
/doc/{ano}/Atividade
/doc/{ano}/Atividade/{codigo}
/doc/{ano}/CategoriaEconomica
/doc/{ano}/CategoriaEconomica/{codigo}
/doc/{ano}/ElementoDespesa
/doc/{ano}/ElementoDespesa/{codigo}
/doc/{ano}/Esfera
/doc/{ano}/Esfera/{codigo}
/doc/{ano}/Exercicio
/doc/{ano}/Exercicio/{identificador}
/doc/{ano}/FonteRecursos
/doc/{ano}/FonteRecursos/{codigo}
/doc/{ano}/Funcao
/doc/{ano}/Funcao/{codigo}
/doc/{ano}/GrupoNatDespesa
/doc/{ano}/GrupoNatDespesa/{codigo}
/doc/{ano}/IdentificadorUso
/doc/{ano}/IdentificadorUso/{codigo}
/doc/{ano}/ItemDespesa
/doc/{ano}/ItemDespesa/{codigo}
/doc/{ano}/ModalidadeAplicacao
/doc/{ano}/ModalidadeAplicacao/{codigo}
/doc/{ano}/OperacaoEspecial
/doc/{ano}/OperacaoEspecial/{codigo}
/doc/{ano}/Orgao
/doc/{ano}/Orgao/{codigo}
/doc/{ano}/PlanoOrcamentario
/doc/{ano}/PlanoOrcamentario/{codigo}
/doc/{ano}/Programa
/doc/{ano}/Programa/{codigo}
/doc/{ano}/Projeto
/doc/{ano}/Projeto/{codigo}
/doc/{ano}/ResultadoPrimario
/doc/{ano}/ResultadoPrimario/{codigo}
/doc/{ano}/Subfuncao
/doc/{ano}/Subfuncao/{codigo}
/doc/{ano}/Subtitulo
/doc/{ano}/Subtitulo/{codigo}
/doc/{ano}/UnidadeOrcamentaria
/doc/{ano}/UnidadeOrcamentaria/{codigo}
5.4 Examples
This section will present a selection of examples of implementations of Linked Data.
5.4.1 DBpedia
DBpedia [52] treats Wikipedia as a database and its objective is to extract structured information from Wikipedia and make this information available on the Web. DBpedia enables sophisticated queries to be made against structured data contained in articles from Wikipedia and links the various datasets on the Web to articles from Wikipedia. Articles from Wikipedia consist primarily of free text, but they also contain different types of structured information, such as info boxes, categorization information, images, geographic coordinates and links to web pages.
The DBpedia project extracts various types of structured information from editions of Wikipedia in 125 languages and combines this information in a large knowledge base. Each entity (resource) in the DBpedia dataset is denoted by a dereferenceable URI, in the form “http:dbpedia.org/resource/{name}”, where “{name}” is derived from the URL of the source article in Wikipedia, which has the form “http://en.wikipedia.org/wiki/{name}”. Thus, each entity of DBpedia is directly linked to an article from Wikipedia. Each DBpedia entity {name} returns a description of a resource in the form of a web document.
For example, the resource http:dbpedia.org/resource/Tim_Berners-Lee” from DBpedia is related to the article “ http://en.wikipedia.org/wiki/Tim_Berners-Lee from Wikipedia. Figures 5.13 and 5.14 present the Wikipedia page for Tim Berners-Lee and the highlighted info box. Figures 5.15 and 5.16 present the DBpedia page for Tim Berners-Lee (Tim_Berners-Lee resource) and a highlight of some of the properties and values extracted from the Wikipedia page. The information from DBpedia can be obtained in different formats. Figure 5.17 presents part of the triples in Turtle format.




@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix dbpprop: <http://dbpedia.org/property/> .
dbpedia:Tim_Berners-Lee
rdf:type foaf:Person ;
foaf:name "Sir Tim Berners-Lee"@en ;
dbpprop:awards "*OM \n*KBE \n*OBE \n*RDI \n*FRS \n*FREng"@en ;
foaf:depiction ;
<http://commons.wikimedia.org/wiki/Special:FilePath/Tim_Berners-Lee_ 2012.jpg>;
dbpprop:birthName "Timothy John Berners-Lee"@en ;
dbpprop:dateOfBirth "1955-06-08+02:00"^^xsd:date ;
dbpprop:placeOfBirth "London, England"@en ;
dbpprop:occupation dbpedia:Computer_scientist ;
dbpedia-owl:employer
dbpedia:Massachusetts_Institute_of_Technology ,
dbpedia:World_Wide_Web_Consortium ,
dbpedia:University_of_Southampton ,
dbpedia:Plessey ;
dbpedia-owl:title "Professor"@en ;
dbpprop:partner "Rosemary Leith"@en ;
dbpedia-owl:parent
dbpedia:Mary_Lee_Woods ,
dbpedia:Conway_Berners-Lee ;
dc:description "British computer scientist, known as the inventor of the World Wide Web" ;
...
dbpedia:Mary_Lee_Woods dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:Conway_Berners-Lee dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web_Consortium dbpprop:leaderName
dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:Libwww dbpprop:author dbpedia:Tim_Berners-Lee .
dbpedia:ENQUIRE dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:WorldWideWeb dbpedia-owl:developer dbpedia:Tim_Berners-Lee .
The data contained in DBpedia can also be obtained through a SPARQL endpoint query [53], implemented with the Openlink Virtuoso application. The data can be accessed through different forms, including Leipzig query builder [54], Open Link interactive query builder (iSPARQL) [55], and SNORQL query explorer [34].
Different applications [56] make use of information contained in DBpedia, such as DBpedia Spotlight [57], which suggests links for DBpedia resources from a free-style text. Taking the text in Figure 5.18 as an example, Spotlight suggests the text in Figure 5.19 with various links to DBpedia, including a link to a resource that describes the World Wide Web [58].
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL or TBL) (London, June 8, 1951)is a British physicist, computer scientist and professor at MIT. He is the creator of the World Wide Web (Internet), who made his first proposal for its creation on March 25, 1989.On December 25, 1990, with the help of Robert Cailliau and a young student from CERN, he implemented the first successful communication between an HTTP client and the server through the Internet.
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL or TBL) (London, June 8, 1951) is a British physicist, computer scientist and professor at MIT. He is the creator of the World Wide Web (Internet), who made his first proposal for its creation on March 25, 1989. On December 25, 1990, with the help of Robert Cailliau and a young student from CERN, he implemented the first successful communication between an HTTP client and the server through the Internet.
5.4.2 Linked Data from the National Library of Spain
The target audience of the datos.bne.es project [59] of the National Library of Spain and the Ontology Engineering Group [60] of the Technical University of Madrid are end users of the library as well as software developers specializing in the Semantic Web. It is a pilot project that proposes an approach to and exploration of bibliographic data that is different from traditional catalogs, offering a new browsing experience for various resources from the library, enriching its own data with external data.
The data can be accessed from the portal or from a SPARQLquery interface [61]. Complete data dumps can also be obtained. The data defined in the application follows the data model of an ontology [62] developed by the Ontology Engineering Group of the Technical University of Madrid.
Figures 5.20 and 5.21 show the project’s homepage and the search page for authors, works or themes. Figures 5.22 and 5.23 present the page resulting from the search for the author “Miguel de Cervantes” and the selection of his work “Don Quijote de la Mancha.” Figure 5.24 presents a highlight from Figure 5.23, which shows how the information is presented as a set of values of properties from the resource “Don Quijote de la Mancha.”





5.4.3 BBC Things
BBC Things [63] uses Semantic Web technologies that permit access to things that are important for the public of the BBC group, such as people, places, organizations, sports competitions, and study topics. BBC has its own set of ontologies [64] that define the types of things that can be queried on BBC Things.
Figures 5.25 and 5.26 present the HTML page resulting from a query on the topic “Madonna” and the code exported in Turtle. The HTML code returned by the query has information from the triples associated with the resource embedded in RDFa.

@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix core: <http://www.bbc.co.uk/ontologies/coreconcepts/> .
@prefix mo: <http://purl.org/ontology/mo/> .
@base <http://www.bbc.co.uk/things/> .
:aead1a21-a0da-47a0-a1b3-ee8957960805#id>
a mo:MusicArtist ;
rdfs:label "Madonna"@en-gb ;
core:preferredLabel "Madonna"@en-gb ;
core:disambiguationHint "Music Artist"@en-gb ;
core:primaryTopicOf
<http://www.bbc.co.uk/music/artists/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://www.madonna.com/> ,
<http://en.wikipedia.org/wiki/Madonna_(entertainer)> ,
<http://www.imdb.com/name/nm0000187/> ;
core:sameAs
<http://dbpedia.org/resource/Madonna_(entertainer)> ,
<http://www.wikidata.org/entity/Q1744> ,
<http://musicbrainz.org/artist/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://rdf.freebase.com/ns/m.01vs_v8> .
5.4.4 Federal Budget of the Brazilian Government
The Brazilian annual budget law (Lei Orçamentária Annual, or LOA in Portuguese acronyms) estimates revenues and sets the government’s expenses for the coming year, and provides a forecast of the actions planned by the government for the fiscal year, corresponding to the period from January 1 to December 31. The annual budget seeks to implement the goals and targets proposed in the Multi-Year Plan (Plano Plurianual, or PPA in Portuguese acronyms), in accordance with the guidelines established by the Budget Guidelines Law (Lei de Diretrizes Orçamentárias, or LDO in Portuguese acronyms).
The Federal Government published the federal budget in RDF format (from 2000 to 2013) in order to provide greater transparency and access to data, so that citizens and organizations interested in better understanding of the federal budget could conduct research and analyses quickly and efficiently. The strategy adopted in the Federal Government project “Federal Budget in Open Format” was to create an ontology [65] based on the classification of expenditures in the federal budget, covering the categories and concepts specified in the Budget Technical Manual [66].
Information about the budget can be obtained from the data catalog [67], which provides access to different datasets:
• Data dumps by year (2000 to 2013).
• Access to different URI patterns [68], for example, the list of expense items from 2014: http://orcamento.dados.gov.br/doc/2014/ItemDespesa.
• Queries against theSPARQL endpoint [69] of the project, such as:
SELECT ?nomeFuncao (sum (?DotacaoInicial)) as ?soma
WHERE
{ ?item rdf:type loa:ItemDespesa .
?item loa:temExercicio [loa:identificador 2014] .
?item loa:temFuncao [rdfs:label ?nomeFuncao] .
?item loa:valorDotacaoInicial ?DotacaoInicial.
?item loa:valorDotacaoInicial ?DotacaoInicial. }
GROUP BY ?nomeFuncao
5.4.5 Bio2RDF
Biological researchers are often faced with the inevitable task of having to integrate their experimental results with the results of other researchers. This task usually involves a tedious manual search and the assimilation of various individual life sciences data collections, hosted by various independent providers. These providers include organizations such as the National Center for Biotechnology Information (NCBI) and the European Bioinformatics Institute (EBI), which provide dozens of datasets sent by users, as well as smaller institutions, such as the Donaldson Group, which publishes iRefIndex3, a molecular interaction database compiled from 13 different data sources.
With thousands of biological databases and hundreds of thousands of datasets, finding relevant data is hindered by non-standardized database interfaces and a huge number of heterogeneous data formats. Furthermore, metadata about these biological data providers (dataset information, data sources, version control, licensing information, creation date, etc.) is often difficult to obtain. As a whole, the inability to easily navigate available data represents a huge barrier for its reuse.
Bio2RDF [70] is an open data project which uses Semantic Web technologies to enable distributed queries against integrated life sciences data. Since its inception, Bio2RDF has made use of RDF and RDFS to unify the representation of data obtained from different fields (molecules, enzymes, diseases, etc.) and biological data stored in heterogeneous formats (text files, CSV files, specific database formats, XML, etc.). Once converted to RDF, this biological data can be queried using SPARQL, which can be utilized for performing federated queries against different SPARQL endpoints.
Bio2RDF currently contains 35 datasets, including the DrugBank [71], which is a bioinformatic and chemoinformatic resource bank that combines detailed data on drugs (chemistry, pharmacology, pharmaceutics, etc.) with information such as sequence, structure etc. Each of the datasets has a SPARQL endpoint and uses vocabulary sets pertaining to that domain. BioPortal [72] provides an enormous list of specific vocabularies for each of the areas.
Figures 5.27 and 5.28 present the results of a query on “Glutahione” on the DrugBank website [73] and against the associated SPARQL endpoint [74].

