5. Dados Conectados
En los capítulos anteriores de esta guía, vimos la evolución de la Web de Documentos hacia una Web de Datos, y las tecnologías utilizadas para agregar semántica de manera tal de ayudar a la manipulación de esas informaciones por parte de las aplicaciones. El horizonte que se pretende alcanzar es el de un banco de datos global, en el cual una gran cantidad de aplicaciones pueda acceder a un conjunto creciente de informaciones con los propósitos más diversos.
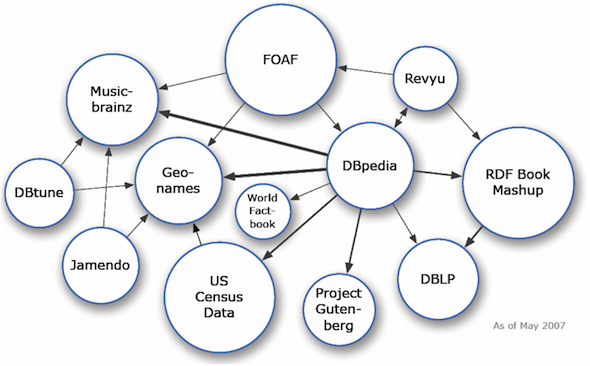
Los datos son publicados en la Web por diferentes personas, y están almacenados en diversas localizaciones a lo largo de todo el mundo. Para facilitar la construcción de ese banco de datos global, es necesario establecer una manera estándar de conexión entre los datos. En este capítulo se presentarán los principios de lo que dio en llamarse Datos Conectados. La aplicación de dicho concepto se expande de manera veloz, y su evolución es habitualmente ilustrada por la figura de una nube, la nube de la LOD (Linked Open Data) [43], que muestra un conjunto de nodos, que a su vez representan conjuntos de datos abiertos, y links, que representan las conexiones establecidas entre estos conjuntos de datos. Las figuras 5.1 y 5.2 muestran la nube en 2007 y 2014, respectivamente.

{kind=link}

Es simple determinar la gran expansión de la nube y la importancia del conjunto de datos en la DBpedia (nodo central de la nube de 2014, con el mayor número de conexiones), que contiene datos representados en RDF relativos a las informaciones incluidas en las cajas de informaciones de los artículos de la Wikipedia.
Los 4 Principios
La idea de agregarles semántica a los datos no es suficiente para la creación de un banco de datos global. Para ello, es necesario que esos datos estén conectados. En 2006, Tim Berners-Lee definió una lista de 4 principios[44] para la conexión de datos:
• Use URIs para identificar las cosas (recursos).
• Use HTTP URIs, de modo tal de posibilitar que las personas puedan buscar esas cosas en la Web.
• Cuando alguien esté buscando una URI, bríndele informaciones relevantes utilizando los estándares (RDF, SPARQL).
• Incluya links a otras URIs, para facilitar que puedan descubrirse otras cosas.
Como vimos anteriormente, las URIs son utilizadas para la identificación de recursos, que pueden representar cualquier cosa, sea concreta o abstracta. El modelo RDF defina una forma de representar el conocimiento mediante tripletas, que pueden definir valores literales para las propiedades, o también establecer relaciones entre los diversos recursos, las diversas cosas.
El hecho de que utilicemos HTTP URIs permite que esa identificación sea utilizada para efectuar una requisición vía Web. Lo que el tercer principio establece es que, una vez realizada la requisición utilizando una de esas URIs (desreferenciación), el servidor responsable de la atención de ese pedido debe devolver algún tipo de información relacionada al recurso identificado por la URI. Como fue visto en la sección que presenta los conceptos de SPARQL, la devolución de una requisición de estas características podría ser algo del tipo del comando DESCRIBE, en el cual se devuelven las tripletas donde el recurso identificado por la URI puede aparecer como sujeto, predicado u objeto. Una forma más simple sería el hecho de tener un archivo RDF estático, con las tripletas consideradas útiles. Este principio no establece qué es lo que debe ser devuelto. Esa decisión es una atribución del servidor Web que atiende la requisición.
El cuarto y último principio establece la conexión propiamente dicha entre los datos. Instituye que, siempre que sea posible, un conjunto de datos debe hacer referencia a otros conjuntos, de manera tal de permitir una navegación entre los diversos nodos de la nube. Por ejemplo, el portal de la DBpedia contiene informaciones sobre recursos que representan personas, países, etc. En caso de que algún otro conjunto de recursos, por ejemplo el portal de la BBC Music, quiera referenciar informaciones sobre los artistas que aparecen en sus programaciones, podrá incluir links entre sus recursos y los de la DBpedia. Es decir, tripletas contenidas en el conjunto de datos de la BBC Music harán referencia a URIs de recursos contenidos en tripletas de la DBpedia.
5.2 Las 5 Estrellas
La Web de Datos es actualmente un espacio heterogéneo, en el cual diferentes tipos de informaciones son publicadas en los más diversos formatos y estructuras de almacenamiento. Contamos con datos almacenados en archivos de tipos diversos, datos almacenados en bancos de datos y devueltos como páginas Web, Web Services y Web APIs, datos almacenados en bancos de tripletas, endpoints SPARQL, etc.
Como modo de orientar la publicación de datos abiertos en la Web de acuerdo a esta nueva visión semántica, Tim Berners-Lee sugirió un esquema de clasificación de 5 estrellas [45], a través del cual se trata un camino evolutivo en dirección a ese universo de Datos Conectados, una Web de Datos en la que todas las informaciones estarían conectadas de acuerdo con los 4 principios.
Esa escala está compuesta por 5 niveles:
1. Publique su información en la Web (cualquiera sea el formato), bajo un tipo de licencia de datos abiertos.
2. Publique esa información en forma de datos estructurados (por ejemplo, una planilla de Excel, o bien, al menos, una imagen digital de una tabla).
3. Use formatos no propietarios (por ejemplo, una tabla CSV en vez de una planilla de Excel).
4. Use URIs para identificar las cosas, de manera que las personas puedan referenciar sus informaciones.
5. Establezca la conexión entre sus datos y otros datos, con el fin de ofrecer un contexto ampliado para las informaciones.
Cada uno de esos niveles presenta costos y beneficios que incluyen, por ejemplo, simplicidad de procedimientos, conversión de datos, formación de personal calificado, etc., todo eso con la intención de dirigirnos hacia un conjunto de datos semánticamente mejor descriptos, y conectados con otros datos. A continuación, se presenta un ejemplo de cómo un mismo conjunto de datos podría publicarse dentro de cada uno de los niveles de la clasificación de "5 Estrellas".
La figura 5.3, muestra un ejemplo de una publicación "1 Estrella": una imagen de una tabla publicada en un archivo .pdf. Esa información puede ser fácilmente procesada por humanos, pero a la vez, es de difícil comprensión por parte de las aplicaciones.
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
La figura 5.4, muestra la misma información, pero publicada en una planilla de cálculo de Excel, lo cual facilitaría el procesamiento de esta información por parte de las aplicaciones. Sin embargo, utiliza aún un formato propietario, por lo cual es aún una publicación "2 Estrellas".
| Tempeature forecast for Galway, Ireland | |
|---|---|
| Day | Lowest Temperature (ºC) |
| Saturday, 13 November 2010 | 2 |
| Sunday, 14 November 2010 | 4 |
| Monday, 15 November 2010 | 7 |
La figura 5.5 ofrece la misma información, pero publicada en un archivo de formato CSV (un formato no propietario), tratándose, en consecuencia, de una publicación "3 Estrellas".
Day,Lowest Temperature (C)
"Saturday, 13 November 2010",2
"Sunday, 14 November 2010",4
"Monday, 15 November 2010",7
La clasificación de "4 Estrellas" determina el avance del nivel de las publicaciones a un estadio adherido a la Web Semántica. En el caso del ejemplo utilizado, podríamos asociar los elementos de las células a las propiedades de determinados vocabularios. La figura 5.6 se presenta como una página Web [46] podría ser visualizada por los usuarios con la información sobre el pronóstico meteorológico dispuesto en forma de tabla.

La figura 5.7 presenta parte del código HTML, con agregados de RDFa incluidos, como modo de agregarle información semántica a los datos. Uno de los vocabularios definidos es el meteo meteo [47], que define un conjunto de propiedades para eventos meteorológicos.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<table border="1px">
<tr>
<th>Day</th>
<th>Lowest Temperature (°C)</th>
</tr>
<tr rel="meteo:forecast" resource="#forecast20101113">
<td>
<div about="#forecast20101113">
<span property="meteo:predicted"
content="2010-11-13T00
datatype="xsd:dateTime">Saturday, 13 November 2010
</span>
</div>
</td>
<td rel="meteo:temperature">
<div about="#temp20101113">
<span property="meteo:celsius"
datatype="xsd:decimal">2</span>
</div>
</td>
</tr>
...
La figura 5.8 muestra las tripletas extraídas de la página, que también pueden visualizarse utilizando el navegador RDF Graphite [48].
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix meteo: <http://purl.org/ns/meteo>
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
rdf:type meteo:Place ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 .
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
La clasificación "5 Estrellas" referencia la inserción de las informaciones en el universo de los Datos Conectados. En el caso del ejemplo utilizado, fue realizada una conexión entre los datos publicados en la página con datos publicados acerca de la ciudad de Galway en la DBpedia, utilizando la propiedad “owl:sameAs”, que indica que las dos URIs hacen referencia a una misma cosa. También se creó un nuevo recurso ("#temp"), que realiza la conexión de "temperatura" con las informaciones definidas en la DBpedia.
Las figuras 5.9 y 5.10 muestran las nuevas inserciones, en relación al ejemplo de “4 Estrellas”.
<html xmlns:xsd ="http://www.w3.org/2001/XMLSchema#"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:meteo="http://purl.org/ns/meteo#">
<h1 property="dcterms:title">Temperature forecast for Galway,Ireland</h1>
<div id="data" about="#Galway" typeof="meteo:Place">
<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Galway">
</span>
<table border="1px">
<tr>
<th>Day</th>
<th>
<div about="#temp">Lowest
<a rel="rdfs:seeAlso"
href="http://en.wikipedia.org/wiki/Temperature"
resource="http://dbpedia.org/resource/Temperature">
Temperature
</a>
(<span rel="owl:sameAs"
resource="http://dbpedia.org/resource/Celsius">
°C</span>)
</div>
</th>
</tr>
...
@base <http://5stardata.info/gtd-4.html> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix dbp: <http:/dbpedia.org/resource/> .
@prefix meteo: <ttp://purl.org/ns/meteo> .
@prefix xhv: <http://www.w3.org/1999/xhtml/vocab#> .
:
dcterm:title "Temperature forecast for Galway, Ireland" ;
xhv:stylesheet <http://5stardata.info/style.css> ;
dcterm:data "2012-01-22"^^xsd:date ;
dcterm:creator <https://github.com/mhausenblas> .
:Galway
df:type meteo:Place ;
owl:sameAs dbp:Galway ;
meteo:forecast :forecast20101113 ;
meteo:forecast :forecast20101114 ;
meteo:forecast :forecast20101115 .
:forecast20101113
meteo:predicted "2010-11-13T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101113 ;
:forecast20101114
meteo:predicted "2010-11-14T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101114 .
:forecast20101115
meteo:predicted "2010-11-15T00:00:00Z"^^xsd:dateTime ;
meteo:temperature :temp20101115 .
:temp
owl:sameAs dbr:Celsius ;
rdfs:seeAlso dbr:Temperature .
:temp20101113 meteo:celsius "2"^^xsd:decimal .
:temp20101114 meteo:celsius "4"^^xsd:decimal .
:temp20101115 meteo:celsius "7"^^xsd:decimal .
5.3 Linked Data API
Uno de los 4 principios de los Datos Conectados establece que cuando se hace el acceso a una URI de un recurso, por ejemplo de una escuela, deben devolverse informaciones relevantes sobre el recurso identificado (desreferenciación). Esas informaciones pueden estar almacenadas, por ejemplo, en archivos estáticos que incluyan el conjunto de tripletas que el servidor Web interpreta como de importancia en referencia al recurso. Sin embargo, muchas veces las informaciones son construidas de manera dinámica a partir de consultas a un SPARQL endpoint. Ello implica que los usuarios de las consultas SPARQL deben contar con una comprensión del esquema de los datos y de los vocabularios utilizados, que no siempre es simple de entender.
La idea de la Linked Data API (LD API) [49] es la de ofrecer una manera sencilla de acceder a Datos Conectados por vía Web, permitiendo que los conjuntos de recursos sean expuestos como URIs, fáciles de consultar, siendo posible también que sean filtradas, paginadas y ordenadas, utilizando parámetros de consulta bastante fáciles. La LD API soporta diversos formatos de resultados, incluyendo JSON, XML, RDF/XML y Turtle.
La LD API es una especificación para una capa intermediaria de software que se apoya en un SPARQL endpoint y ofrece una Web API para acceder a los datos. El mapeo es configurado por el administrador del servidor de datos, y atiende estándares de nomenclatura, tales como http://orcamento.dados.gov.br/doc/{ano}/ItemDespesa, en donde {ano} (año, en portugués) puede ser substituido, de modo tal de obtener los resultados específicos para un determinado período: http://orcamento.dados.gov.br/doc/2013/ItemDespesa. La figura 5.11 muestra la consulta que debería efectuarse para la obtención de las tripletas relativas a esa información.
PREFIX loa: http://vocab.e.gov.br/2013/09/loa#>
SELECT ?item
WHERE {
?item loa:temExercicio [loa:identificador 2013]. } OFFSET 0 LIMIT 6
De esta misma manera, pueden especificarse estándares de URIs que acepten como parámetros a informaciones definidas en la URI para acceder a los recursos. Por ejemplo, el portal que permite acceder a los datos del presupuesto federal brasileño [50] acepta los estándares de URIs expresados en la figura 5.12.
La LD API es una especificación de código abierto, y existen algunos productos que la implementan; entre ellos está el Elda [51] de la Epimorphics.
/doc/{ano}/Acao
/doc/{ano}/Acao/{codigo}
/doc/{ano}/Atividade
/doc/{ano}/Atividade/{codigo}
/doc/{ano}/CategoriaEconomica
/doc/{ano}/CategoriaEconomica/{codigo}
/doc/{ano}/ElementoDespesa
/doc/{ano}/ElementoDespesa/{codigo}
/doc/{ano}/Esfera
/doc/{ano}/Esfera/{codigo}
/doc/{ano}/Exercicio
/doc/{ano}/Exercicio/{identificador}
/doc/{ano}/FonteRecursos
/doc/{ano}/FonteRecursos/{codigo}
/doc/{ano}/Funcao
/doc/{ano}/Funcao/{codigo}
/doc/{ano}/GrupoNatDespesa
/doc/{ano}/GrupoNatDespesa/{codigo}
/doc/{ano}/IdentificadorUso
/doc/{ano}/IdentificadorUso/{codigo}
/doc/{ano}/ItemDespesa
/doc/{ano}/ItemDespesa/{codigo}
/doc/{ano}/ModalidadeAplicacao
/doc/{ano}/ModalidadeAplicacao/{codigo}
/doc/{ano}/OperacaoEspecial
/doc/{ano}/OperacaoEspecial/{codigo}
/doc/{ano}/Orgao
/doc/{ano}/Orgao/{codigo}
/doc/{ano}/PlanoOrcamentario
/doc/{ano}/PlanoOrcamentario/{codigo}
/doc/{ano}/Programa
/doc/{ano}/Programa/{codigo}
/doc/{ano}/Projeto
/doc/{ano}/Projeto/{codigo}
/doc/{ano}/ResultadoPrimario
/doc/{ano}/ResultadoPrimario/{codigo}
/doc/{ano}/Subfuncao
/doc/{ano}/Subfuncao/{codigo}
/doc/{ano}/Subtitulo
/doc/{ano}/Subtitulo/{codigo}
/doc/{ano}/UnidadeOrcamentaria
/doc/{ano}/UnidadeOrcamentaria/{codigo}
5.4 Ejemplos
En esta sección se presentará una selección de ejemplos de implementaciones de Datos Conectados.
5.4.1 DBpedia
La DBpedia [52] toma a la Wikipedia como un banco de datos. Tiene como objetivo extraer informaciones estructuradas de dicha plataforma y hacerlas disponibles en la Web. La DBpedia permite realizar consultas avanzadas sobre los datos estructurados incluidos en la Wikipedia y relacionar los diferentes conjuntos de datos en la Web con los artículos de la Wikipedia. Estos últimos consisten, fundamentalmente, de texto libre; pero también incluyen diversos tipos de informaciones estructuradas, tales como cajas de información, informaciones de categorización, imágenes, coordenadas geográficas y links hacia otras páginas de la Web.
El proyecto DBpedia extrae variados tipos de informaciones estructuradas de ediciones de la Wikipedia en 125 idiomas, y combina dicha información en una gran base de conocimiento. Cada entidad (recurso) en el conjunto de datos de la DBpedia es denotado por una URI desreferenciable, que responda al formato “http:dbpedia.org/resource/{nombre}”, donde “{nombre}” deriva del artículo original de la Wikipedia, que tiene el formato “http://en.wikipedia.org/wiki/{nombre}”. De esa manera, cada entidad de la DBpedia está conectada en forma directa a un artículo de la Wikipedia. Cada {nombre} de entidad DBpedia devuelve la descripción de un recurso en formato de documento Web.
Por ejemplo, el recurso http:dbpedia.org/resource/Tim_Berners-Lee” de la DBpedia está relacionado al artículo “ http://en.wikipedia.org/wiki/Tim_Berners-Lee de la Wikipedia. Las figuras 5.13 y 5.14 muestran, respectivamente, la página de la Wikipedia de Tim Berners-Lee y la caja de informaciones, destacada. Las figuras 5.15 y 5.16 muestran, respectivamente, la página de la DBpedia de Tim Berners-Lee (recurso Tim_Berners-Lee) y el resaltado de algunas de las propiedades y valores extraídos de la página de la Wikipedia. Las informaciones e la DBpedia pueden obtenerse en diferentes formatos. La figura 5.17 presenta parte de las tripletas en formato Turtle.




@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix dbpprop: <http://dbpedia.org/property/> .
dbpedia:Tim_Berners-Lee
rdf:type foaf:Person ;
foaf:name "Sir Tim Berners-Lee"@en ;
dbpprop:awards "*OM \n*KBE \n*OBE \n*RDI \n*FRS \n*FREng"@en ;
foaf:depiction ;
<http://commons.wikimedia.org/wiki/Special:FilePath/Tim_Berners-Lee_ 2012.jpg>;
dbpprop:birthName "Timothy John Berners-Lee"@en ;
dbpprop:dateOfBirth "1955-06-08+02:00"^^xsd:date ;
dbpprop:placeOfBirth "London, England"@en ;
dbpprop:occupation dbpedia:Computer_scientist ;
dbpedia-owl:employer
dbpedia:Massachusetts_Institute_of_Technology ,
dbpedia:World_Wide_Web_Consortium ,
dbpedia:University_of_Southampton ,
dbpedia:Plessey ;
dbpedia-owl:title "Professor"@en ;
dbpprop:partner "Rosemary Leith"@en ;
dbpedia-owl:parent
dbpedia:Mary_Lee_Woods ,
dbpedia:Conway_Berners-Lee ;
dc:description "British computer scientist, known as the inventor of the World Wide Web" ;
...
dbpedia:Mary_Lee_Woods dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:Conway_Berners-Lee dbpprop:children dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web_Consortium dbpprop:leaderName
dbpedia:Tim_Berners-Lee .
dbpedia:World_Wide_Web dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:Libwww dbpprop:author dbpedia:Tim_Berners-Lee .
dbpedia:ENQUIRE dbpprop:inventor dbpedia:Tim_Berners-Lee .
dbpedia:WorldWideWeb dbpedia-owl:developer dbpedia:Tim_Berners-Lee .
Los datos incluidos en la DBpedia también pueden obtenerse a través de consultas a un SPARQL endpoint query [53], implementado con la aplicación Virtuoso de la Openlink. Podría accederse a los datos de diversas maneras, incluyendo el constructor de consultas Leipzig [54], constructor de consultas interactivo Openlink (iSPARQL) [55], y el explorador de consultas SNORQL [34].
Existen diversas aplicaciones [56] que hacen uso de las informaciones alojadas en la DBpedia, como por ejemplo el DBpedia Spotlight [57], que, a partir de un texto ofrecido en estilo libre, sugiere links para los recursos de la DBpedia. Tomando como ejemplo al texto de la figura 5.18, el Spotlight sugiere el texto de la figura 5.19 con diversos links hacia la DBpedia (en ese caso, en portugués), incluyendo un link al recurso que describe la World Wide Web [58].
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL or TBL) (London, June 8, 1951)is a British physicist, computer scientist and professor at MIT. He is the creator of the World Wide Web (Internet), who made his first proposal for its creation on March 25, 1989.On December 25, 1990, with the help of Robert Cailliau and a young student from CERN, he implemented the first successful communication between an HTTP client and the server through the Internet.
Sir Timothy John Berners-Lee KBE, OM, FRS (TimBL or TBL) (London, June 8, 1951) is a British physicist, computer scientist and professor at MIT. He is the creator of the World Wide Web (Internet), who made his first proposal for its creation on March 25, 1989. On December 25, 1990, with the help of Robert Cailliau and a young student from CERN, he implemented the first successful communication between an HTTP client and the server through the Internet.
5.4.2 Datos Conectados de la Biblioteca Nacional de España
El proyecto datos.bne.es project [59] de la Biblioteca Nacional de España y del Ontology Engineering Group [60] de la Universidad Politécnica de Madrid tiene como público objetivo tanto a los usuarios finales de la biblioteca como a los desarrolladores de aplicaciones especializados en la Web Semántica. Se trata de un proyecto piloto que busca proponer un abordaje y una exploración de los datos bibliográficos diferente a la de los catálogos tradicionales, ofreciendo una nueva experiencia de navegación por los diferentes recursos de la biblioteca y enriqueciendo sus propios datos con otros datos externos.
Puede accederse a los datos a partir del propio portal o desde una interfaz SPARQL [61]. Además, también pueden obtenerse dumps completos de los datos. Los datos definidos en la aplicación responden al modelo de datos de una ontologia [62] desarrollada por el Ontology Engineering Group de la Universidad Politécnica de Madrid.
Las figuras 5.20 y 5.21 muestran, respectivamente, la página inicial del proyecto y la página de búsqueda de autores, obra o temas. Las figuras 5.22 y 5.23 presentan la página obtenida de la búsqueda del autor "Miguel de Cervantes Saavedra" y la selección de su obra "Don Quijote de la Mancha". La figura 5.24 detalla una parte de la figura 5.23 en la cual es posible observar cómo se presentan las informaciones en el formato de un conjunto de valores de propiedades del recurso "Don Quijote de la Mancha".





5.4.3 BBC Things
BBC Things [63] utiliza tecnologías de Web Semántica que permiten acceder a asuntos de importancia para el público del grupo BBC, tales como personas, lugares, organizaciones, competencias deportivas, temáticas de estudio, etc. La BBC posee un conjunto propio de ontologias [64] que definen los tipos de asuntos que pueden ser consultados en BBC Things.
Las figuras 5.25 y 5.26 muestran la página HTML resultante de una consulta al tópico "Madonna" y el código exportado en Turtle. El código HTML devuelto por la consulta incluye las informaciones de las tripletas asociadas al recurso, embutidas en RDFa.

@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix core: <http://www.bbc.co.uk/ontologies/coreconcepts/> .
@prefix mo: <http://purl.org/ontology/mo/> .
@base <http://www.bbc.co.uk/things/> .
:aead1a21-a0da-47a0-a1b3-ee8957960805#id>
a mo:MusicArtist ;
rdfs:label "Madonna"@en-gb ;
core:preferredLabel "Madonna"@en-gb ;
core:disambiguationHint "Music Artist"@en-gb ;
core:primaryTopicOf
<http://www.bbc.co.uk/music/artists/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://www.madonna.com/> ,
<http://en.wikipedia.org/wiki/Madonna_(entertainer)> ,
<http://www.imdb.com/name/nm0000187/> ;
core:sameAs
<http://dbpedia.org/resource/Madonna_(entertainer)> ,
<http://www.wikidata.org/entity/Q1744> ,
<http://musicbrainz.org/artist/79239441-bfd5-4981-a70c-55c3f15c1287> ,
<http://rdf.freebase.com/ns/m.01vs_v8> .
5.4.4 Presupuesto Federal el Gobierno Brasileño
La Ley Presupuestaria Anual (LPA, "LOA" en portugués) estima los ingresos y determina el gasto del Gobierno para el año siguiente, además de ofrecer la previsión de las acciones planificadas por el gobierno durante el ejercicio financiero, que corresponde al período entre el 1º de enero y el 31 de diciembre. El Presupuesto Anual apunta a concretar los objetivos y metas propuestas en el Plan Plurianual (PPA), de acuerdo con las directrices establecidas por la Ley de Directrices Presupuestarias (LDP, "LDO" en portugués).
El Gobierno Federal publicó el presupuesto federal en formato RDF (para el período de 2000 a 2013), con el fin de otorgar mayor transparencia y acceso a los datos, permitiendo así que los ciudadanos y las organizaciones interesadas en conocer mejor los datos del presupuesto federal puedan realizar búsquedas y análisis de manera rápida y eficiente. La estrategia adoptada en el proyecto "Presupuesto Federal en formato Abierto" del Gobierno Federal, fue la de crear una ontologia [65] con base en la clasificación del gasto del presupuesto federal, contemplando las categorías y conceptos especificados en el Manual Técnico de Presupuesto [66].
Pueden obtenerse informaciones sobre el presupuesto a partir del catálogo de datos abiertos del gobierno federal [67], Es posible conseguir acceso a diversos conjuntos de datos:
• Dumps de los datos por año (2000 a 2013).
• Acceso a los diversos estándares de URIs [68], por ejemplo, la lista de los ítems de Gasto de 2014: http://orcamento.dados.gov.br/doc/2014/ItemDespesa.
• Consultas al SPARQL endpoint [69] del proyecto, por ejemplo:
SELECT ?nomeFuncao (sum (?DotacaoInicial)) as ?soma
WHERE
{ ?item rdf:type loa:ItemDespesa .
?item loa:temExercicio [loa:identificador 2014] .
?item loa:temFuncao [rdfs:label ?nomeFuncao] .
?item loa:valorDotacaoInicial ?DotacaoInicial.
?item loa:valorDotacaoInicial ?DotacaoInicial. }
GROUP BY ?nomeFuncao
5.4.5 Bio2RDF
Los investigadores biológicos deben enfrentarse con frecuencia a la inevitable tarea de tener que integrar sus resultados experimentales con los resultados de otros investigadores. Esa tarea, normalmente, involucra una tediosa búsqueda manual, y el aprendizaje de diversos conjuntos aislados de datos sobre ciencias biológicas, hospedados por varios colectores independientes. Dentro de estos colectores podemos citar a organizaciones tales como el Centro Nacional de Información Biotecnológica (NCBI, National Center for Biotechnology) y el Instituto Europeo de Bioinformática (EBI, European Bioinformatics Institute), que ofrecen infinidad de conjuntos de datos enviados por usuarios. Existen también instituciones menores, como el grupo Donaldson, que publica iRefIndex3, un banco de datos de interacciones moleculares construido a partir de 13 fuentes de datos diferentes.
Con millares de bancos de datos biológicos y centenares de miles de conjuntos de datos, la capacidad de encontrar datos de relevancia se ve dificultada por el uso de interfaces de bancos de datos no estandarizadas, para una enorme cantidad de formatos de datos heterogéneos. Además, los metadatos sobre dichos proveedores de datos biológicos (información del conjunto de datos, fuentes de los datos, control de la versión, información de la licencia, fecha de creación, etc.) suelen ser muy difíciles de obtener. Tomando el problema en su conjunto, la imposibilidad de navegar de una manera simple entre la enorme cantidad de datos disponibles, acaba por constituirse en una barrera infranqueable para la reutilización de esa información.
Bio2RDF [70] es un proyecto de datos abiertos que aplica tecnologías de la Web Semántica para hacer posible la consulta distribuida de datos integrados de ciencias biológicas. Desde su concepción, Bio2RDF ha hecho uso de RDF y RDFS para unificar la representación de datos obtenidos de diversas áreas (moléculas, enzimas, enfermedades, etc.) y datos biológicos almacenados en formatos heterogéneos (archivos de texto, archivos CSV, formatos específicos de bancos de datos, XML, etc.). Una vez convertidos a RDF, estos datos del campo biológico pueden ser consultados utilizando SPARQL, mediante consultas federadas en diversos SPARQL endpoints.
Actualmente, Bio2RDF reúne 35 conjuntos de datos; entre ellos, el DrugBank [71], un banco de recursos bioinformáticos y químico-informáticos que combina datos detallados sobre drogas (química, farmacología, farmacia, etc.) con informaciones tales como secuencia, estructura, etc. Cada uno de los conjuntos de datos posee un SPARQL endpoint y utiliza conjuntos de vocabularios propios de cada dominio. En BioPortal [72] es posible acceder a la enorme lista de vocabularios específicos para cada una de las áreas.
Las figuras 5.27 y 5.28 muestran, respectivamente, los resultados de una consulta a “Glutathione” en el portal DrugBank [73] y en el SPARQL endpoint [74] asociado.

