1 - Visão Holística: Da Produção ao Consumo de Dados Abertos
Introdução
Saber trabalhar com grandes quantidades de dados procedentes de diversas localidades e com diferentes formatos é uma das habilidades mais desejadas na última década (Davenport, et al., 2012) . Isso ocorre devido ao crescimento exponencial dos dados gerados pela sociedade e a necessidade de minerar informações obtidas por meio da análise das conexões semânticas entre conceitos e relações presentes nestes dados (Isotani, et al., 2009; Bittencourt, et al., 2008) . Para exemplificar essa problemática um estudo desenvolvido pela IDC Digital Universe fez uma medição dos dados criados replicados e consumidos em 2011 e estimou que 1,8 trilhão de gigabytes de dados foram produzidos durante o ano (EMC, 2012) . Contudo, grande parte destes dados não está disponível ao público. Estes dados tampouco estão estruturados para facilitar sua compreensão mesmo por aqueles que podem acessá-los e manipulá-los. Como resultado, a extração de informações e produção de conhecimentos que poderiam ser úteis para sociedade não acontecem com a agilidade e eficácia necessárias para lidar com questões sociais e econômicas do século 21.
Para modificar esta situação, diversas empresas, governos e institutos de pesquisa têm realizado esforços para disponibilizar dados e produzir tecnologias web que permitam criar um ecossistema de produção e consumo de dados com o objetivo de agilizar a descoberta de novos conhecimentos e agregar valor a qualquer informação disponibilizada livremente na Internet.
Neste contexto, o objetivo principal deste texto é fomentar e incentivar a qualificação de profissionais por meio da capacitação teórica, técnica e tecnológica que apoiam a criação e manutenção deste ecossistema. Em particular, focaremos em métodos e ferramentas para modelar e estruturar os dados de maneira adequada (por exemplo, por meio de ontologias) para que estes possam ser utilizados e reutilizados por programas de computador. Além disso, pretende-se apresentar técnicas de desenvolvimento de software utilizando tecnologias avançadas provindas da área de Web Semântica (Berners-Lee, et al., 2001) e Linked Data (Berners-Lee, 2006) para fazer uso efetivo dos dados publicados na Web.
1.1.1 Motivação
Antes de introduzir os conceitos teóricos e técnicos, gostaríamos de iniciar o texto com um exemplo que incentive o leitor a pensar sobre as necessidades e potencialidades de produzir e disponibilizar dados livremente na Web.
Propomos pensar um pouco sobre a gestão de cidades, estados e países. Para manter os vários serviços públicos oferecidos pelo governo, existem diversas informações que precisam ser compartilhadas, integradas e gerenciadas. Por exemplo, o serviço de transporte público urbano possui frotas de ônibus, trens ou metrô, que são concessões municipais, estaduais ou federais. Além disso, existem também as frotas intermunicipais e interestaduais que conectam diferentes municípios e estados. Neste contexto, para utilizar este serviço e verificar se o mesmo está sendo oferecido com qualidade e eficiência desejadas são necessários produção e consumo de dados que normalmente são armazenados em diferentes bases de dados com informações sobre os diversos tipos de transporte em operação.
Imagine que os dados sobre os transportes públicos estejam disponíveis apenas para os técnicos e funcionários autorizados. Isso significa que estes dados não podem ser acessados pelos cidadãos e, portanto, não há como obter informações sobre os horários, rotas e destinos dos transportes públicos, inviabilizando o planejamento das pessoas que precisam utilizar este meio de locomoção.
Contudo, caso os dados sobre os transportes públicos estejam disponíveis livremente na Web em formato aberto, um cidadão poderia ter acesso às informações contidas nestes dados e utilizá-las a seu favor. Por exemplo, poderia planejar uma rota simples da sua casa ao trabalho, utilizando diferentes meios de transporte; poderia também comparar o custo/benefício de diferentes rotas e tipos de transporte. Da mesma forma, um funcionário de um município também usufruiria de benefícios, pois poderia facilmente acessar dados de outros municípios e do estado para realizar suas atividades. Por exemplo, poderia adequar os horários dos transportes locais; alocar mais veículos em horários com maior demanda; e também comparar os dados locais com os de municípios similares para analisar a eficiência do serviço.
Apesar dos benefícios dos dados disponibilizados em formato aberto apresentados no parágrafo anterior, há um grande problema quando surge a necessidade de associar diversos dados ou quando a quantidade de dados é excessiva para interpretação humana. Por exemplo, caso o cidadão queira verificar qual a média de pessoas que pegam um determinado tipo de transporte em um determinado horário para evitar horários de pico em rotas com conexões intermunicipais ou interestaduais, ele seria obrigado a verificar cada uma das bases de dados dos diferentes municípios e/ou estados, para então analisar e planejar manualmente cada uma das conexões e horários, de forma a criar o melhor trajeto para atender as suas necessidades. Este problema pode ser ainda mais complexo para os funcionários que gerenciam o transporte público, pois, para obter as informações sobre os diversos serviços oferecidos pelos municípios, eles teriam que manualmente acessar centenas de bases de dados, que possivelmente possuem informações diferentes, para assim, extrair e compilar as informações desejadas.
Nesse cenário, caso os dados estivessem estruturados e conectados 2 de forma que um computador pudesse processá-los, então as tarefas apresentadas poderiam ser automatizadas (Barros, et al., 2011) . Um aplicativo computacional poderia acessar os dados das diversas bases de municípios, dos estados e da federação para planejar trajetos em qualquer região do país. Seria possível criar também um aplicativo para analisar o transporte público de centenas de municípios para realizar diversas comparações e análises estatísticas que são fundamentais para obter uma visão geral sobre a cobertura e qualidade do serviço realizado. Assim, ao invés de dias, tarefas complexas e trabalhosas poderiam ser realizadas em poucos minutos.
Para que isso ocorra é necessário lidar com diversos desafios, que podem ser resumidos em como gerenciar, coletar, modelar, padronizar e consumir dados adequadamente. Assim, nesta primeira parte do texto apresentaremos os fundamentos teóricos necessários para lidar com estes desafios e para ter uma visão holística e conceitual sobre como criar um ambiente propício para produção e consumo de dados.
1.2 Dados Abertos
Esta seção tem por objetivo fazer uma revisão sobre dados abertos, abordando os conceitos de dados abertos e dados abertos governamentais, sua importância, seus princípios e, finalmente, um panorama sobre dados abertos no Brasil e no mundo.
É importante frisar que esta seção não objetiva estressar a temática de Dados Abertos, tendo em vista que tal conhecimento está disponibilizado no curso Publicação de Dados em Formato Aberto (W3C Brasil, 2013), disponível no site da Escola de Políticas Públicas.
Segundo a Open Defitinion (Open Definition, 2014), dados abertos são dados que podem ser livremente utilizados, reutilizados e redistribuídos por qualquer pessoa - sujeitos, no máximo, à exigência de atribuição à fonte original e compartilhamento pelas mesmas licenças em que as informações foram apresentadas. Ou seja, a abertura de dados está interessada em evitar um mecanismo de controle e restrições sobre os dados que forem publicados, permitindo que tanto pessoas físicas quanto jurídicas possam explorar estes dados de forma livre.
Sob esta perspectiva, a definição do termo dados abertos carrega 3 normas fundamentais (Open Knowledge Foundation, 2010):
• Disponibilidade e acesso: os dados devem estar disponíveis como um todo e sob custo não maior que um custo razoável de reprodução, preferencialmente possíveis de serem baixados pela Internet. Os dados devem também estar disponíveis de uma forma conveniente e modificável;
• Reuso e redistribuição: os dados devem ser fornecidos sob termos que permitam a reutilização e a redistribuição, inclusive a combinação com outros conjuntos de dados;
• Participação universal: todos devem ser capazes de usar, reutilizar e redistribuir - não deve haver discriminação contra áreas de atuação ou contra pessoas ou grupos. Por exemplo, restrições de uso ‘não-comercial’ que impediriam o uso ‘comercial’, ou restrições de uso para certos fins (ex.: somente educativos) excluem determinados dados do conceito de ‘abertos’.
A partir do momento que há um movimento de abrir dados, onde as três normas fundamentais supracitadas são respeitadas, é possível que diferentes organizações e sistemas possam trabalhar de forma colaborativa. Isto ocorre devido à capacidade destas organizações e sistemas em interoperar os dados que foram abertos, ampliando assim a comunicação e potencializando o desenvolvimento eficiente de sistemas complexos. Para tal, os dados devem ser acessíveis, legíveis por máquinas, em formato aberto, e com informação produzida por todos e para todos.
Apesar do movimento de dados abertos ter sido impulsionado mais recentemente, o termo ‘Dados Abertos’ surgiu pela primeira vez em 1995 em um documento de uma agência científica americana, abordando a divulgação de dados ambientais e geofísicos (Chignard, 2013) . No documento, os autores promoveram um completo e aberto intercâmbio de informação científica entre diferentes países como um pré-requisito para a análise e compreensão de fenômenos naturais globais. É importante frisar que o princípio de bens comuns aplicado ao conhecimento já foi teorizado por Robert King Merton, em 1942, onde sua teoria mostrava os benefícios de dados científicos abertos.
Mais recentemente, os dados abertos têm sido estimulados por movimentos globais, como a campanha feita pela Iniciativa Internacional de Transparência em Programas de Assistência (do Inglês International Aid Transparency Initiative) sobre a transparência nos registros dos gastos.
Outro importante acontecimento para o movimento de dados abertos aconteceu em Dezembro de 2007, onde pensadores e ativistas da Internet se reuniram para definir o conceito de Dados Abertos Públicos (ou Governamentais) (Chignard, 2013). A ideia básica desenvolvida foi que os dados governamentais são propriedades comuns, da mesma forma que as ideias científicas. A filosofia por trás do conceito de dados governamentais abertos é inspirada no conceito de código aberto (do Inglês open source), fundamentada por três pilares conceituais: abertura, participação e colaboração.
Essa visão de dados abertos governamentais foi fortalecida em 2008, após um memorando do Presidente Barack Obama sobre Transparência e Dados Governamentais (Obama, 2008) e pela criação do Data.gov, com o objetivo de disponibilizar um portal de dados abertos onde os dados do governo norte-americano poderiam ser acessados na Internet por qualquer cidadão.
Nessa perspectiva, o Governo Brasileiro foi um dos fundadores da Open Government Partnership, criada em 2011 e que conta atualmente com a participação de 65 países. O Governo Brasileiro criou também o dados.gov.br, portal que disponibiliza dados governamentais seguindo os princípios de dados abertos. Os dados abertos governamentais fazem parte da política de acesso à informação do governo federal, (INDA), ambos criados em 2012. A Administração Pública Federal, por meio da Lei de Acesso à Informação, em seu artigo 8º, reconheceu a necessidade de disponibilizar dados governamentais em formato aberto.
1.3 Da Grande Produção de Dados aos Dados Conectados
Eu um estudo realizado em 2003 por pesquisadores da Escola de Gerenciamento de Informação e Sistemas da Universidade de Berkeley, estimou-se que a humanidade tenha acumulado 12 exabytes (12 x 1018) de dados até o momento anterior aos computadores virarem commodities, na década de 90. Entretanto, este mesmo estudo mostrou que somente no ano de 2002, a humanidade produziu mais de 5 exabytes em mídias de armazenamento óptico, magnético, filme e impressão. Esta produção é equivalente à produção de 37 mil novas bibliotecas do tamanho da Biblioteca do Congresso Americano. Destes 5 exabytes produzidos, 92% foram armazenados em mídias magnéticas, maioria em discos rígidos, o que aponta para uma incrível democratização da informação (Floridi, 2010).
A Figura 1.1 apresenta um ciclo de vida típico da informação. Observe a temporalidade presente no ciclo da informação abaixo e como uma informação é consumida para a geração de novos dados que serão consumidos infinitamente. É importante frisar que a geração de novos dados baseada em dados anteriormente consumidos é inerente à sociedade e mostra a importância que a estruturação e a conexão de dados possuem para simplificar e facilitar a recuperação da informação e a produção de novos conhecimentos.

De fato, a informação exerce papel fundamental para o desenvolvimento da sociedade pós-moderna. Ao observar os membros do G7 – Canadá, França, Alemanha, Itália, Japão, Reino Unido e Estados Unidos – todos eles podem ser qualificados como sociedades da informação, pois pelo menos 70% dos seus PIBs dependem de bens intangíveis (bens relacionados à informação) (Floridi, 2010). Ou seja, o funcionamento e o crescimento destas nações dependem da constante geração e consumo de dados de forma massiva.
Em um estudo mais recente, foi destacado que de 2006 a 2010, o número de dados digitais gerados cresceu de 166 exabytes para 988 exabytes. Esta grande quantidade de dados que tem sido gerada já alcançou a casa dos Zettabytes(1000 exabytes ou 1024) em 2014 (Floridi, 2010). Como descrito anteriormente, mais de 90% destes dados estão armazenados em discos rígidos, onde centenas de milhões de computadores, ininterruptamente, estão processando estes dados em busca de informação útil e relevante e, às vezes, nova. Estima-se que em 2020, o volume de dados chegará a 40 Zettabytes, como mostra a Figura 1.2.

Este incrível crescimento de dados faz com que seja fundamental uma cuidadosa análise destes dados e a compreensão sobre quais tipos de dados têm sido gerados nesta sociedade da informação. Os dados digitais estão, de alguma forma, estruturados e têm sido gerados com o intuito de prover informações úteis e gerar novos conhecimentos (vide Figura 1.3).

É importante frisar que muitos desses dados podem ser descobertos e acessados, tanto por seres humanos quanto por máquinas, através da World Wide Web. Em 1989, o físico inglês, Sir Timothy John Berners-Lee, no CERN do francês Conseil Européen pour la Recherche Nucléaire (ou Centro Europeu de Pesquisas Nucleares), inventou a WWW (World Wide Web), através da proposição de três tecnologias fundamentais: o HTML (Hypertext Markup Language); o servidor HTTP (Hypertext Transfer Protocol) e o URI (Unified Resource Identifier). Tais invenções foram motivadas pela necessidade de facilitar o compartilhamento de documentos entre os pesquisadores e visitantes do CERN. Com isso, tanto o lançamento do browser X Windows Mosaic 1.0 quanto a primeira conferência sobre a WWW estimularam a desenvolvimento da Web. Em maio de 1994, houve a primeira conferência internacional sobre a WWW (First International Conference on World Wide Web), em Genebra. Esta conferência simboliza a grande popularização da Web, onde nela foi anunciado o consórcio que cuida dos padrões e tecnologias relacionadas ao desenvolvimento da Web, o W3C (World Wide Web Consortium).
Ainda nesta conferência, Tim Berners-Lee proferiu uma palestra sobre a necessidade de semântica na Web. Segundo Tim Berners-Lee, a forma que os documentos web estavam estruturados (através de nós e links) fazia com que apenas serem humanos pudesse entender o significado contido nelas. Tal impossibilidade fazia com que máquinas não pudessem acessar e obter significado dos documentos. A Figura 1.4 ilustra o relacionamento entre páginas sem semântica explícita.

De forma mais detalhada, os documentos utilizam a linguagem HTML, que é uma linguagem que faz apresentação de hipertextos. Os hipertextos são documentos que possuem links e nós (ou pontos de conexão) com outros documentos, permitindo assim a navega çã o entre os mesmos. Entretanto, os links que existem para relacionar os documentos não tinham nenhum tipo de característica que diferenciasse um do outro, de tal forma que não é possível para as máquinas distinguir o significado entre uma relação e outra.
É importante frisar que tais problemas ficam mais evidentes nos dias de hoje, pois se calculam dezenas de bilhões de páginas web disponíveis e mais de 1 Zettabyte de dados. Esta quantidade de documentos torna praticamente impossível o acesso e a busca por informação de forma eficiente e consistente para os seres humanos, fazendo com que haja a necessidade de entidades de softwares buscarem informações e processarem atividades para os humanos (Bittencourt, et al., 2008). Com isso, a semântica acessível por máquina é potencializada através da especificação de documentos web em uma linguagem que permita que os links sejam criados com valor em seu relacionamento. Isto faz com que os recursos possuam uma semântica associada, permitindo a execução automática de atividades como compra de produtos personalizados, negociação por pacotes turísticos, agendamento de consultas, entre outras. A Figura 1.5 descreve os documentos e os relacionamentos com os recursos.

Passados 5 anos desde sua palestra na conferência WWW, Tim Berners-Lee publicou um Livro intitula: “Weaving the Web”, onde o termo Web Semântica apareceu pela primeira vez. Finalmente, em 2001, o artigo publicado na revista Scientific American marcou o início da pesquisa relacionada à Web Semântica. Tal artigo, intitulado (e traduzido para o Português) “Web Semântica: Um novo formato de conteúdo para a Web que tem significado para computadores vai iniciar uma revolução de novas oportunidades”. Neste artigo, Tim Berners Lee aborda características da Web Semântica, propondo as camadas da Web Semântica e descrevendo como poderia funcionar.
De forma mais detalhada, a Web Semântica busca utilizar recursos provenientes da Inteligência Artificial (como agentes inteligentes e representação de conhecimento), Engenharia de Software (como frameworks e plataformas), Computação Distribuída (como web services), entre outras, para executar atividades na Web que antes só eram possíveis por agentes humanos.
Ou seja, a Web Semântica estende a web clássica, provendo uma estrutura Semântica para páginas web, a qual permite que tanto agentes humanos quanto agentes de software possam entender o conteúdo presente em páginas web. Dessa forma, a Web Semântica provê um ambiente onde agentes de software podem navegar através de páginas web e executar tarefas sofisticadas. Em outras palavras, a Web Semântica é necessária para expressar informações de forma precisa, podendo tais informações serem interpretadas por máquinas e dessa forma permitirem que agentes de software possam processar, compartilhar, reusar, além de poder entender os termos que estão sendo descritos pelos dados (Devedzic, 2006; Isotani, et al., 2009).
Um cenário clássico, ilustrado no artigo de 2001 sobre a Web Semântica, descreve a marcação de uma consulta médica. Nele, basicamente, Lucy precisava marcar uma consulta para a sua mãe e levá-la ao médico. Houve a necessidade de localizar médicos qualificados e com o mesmo plano de saúde que a mãe de Lucy. Ela precisava estar disponível no horário da consulta da mãe e não poderia perder muito tempo com o deslocamento, ou seja, a consulta deveria ser em um local próximo à casa de sua mãe. Logo, Lucy precisaria configurar seu agente para que ele pudesse recuperar o tratamento médico, serviços disponíveis e consultórios próximos àcasa de sua mãe e finalmente, marcar a consulta que melhor se encaixasse com as exigências de Lucy. A Figura 1.6 ilustra alguns dos recursos que podem ser utilizados em um cenário como este. Nela aborda-se a integração de ontologias, agentes inteligentes e serviços semânticos para alcançar o objetiv apresentado neste cenário

Objetivando tornar a visão da Web Semântica mais factível em termos de implementação, Tim Berners-Lee propôs um modelo em camadas, conhecido como "bolo de noiva" ou “pirâmide da Web Semântica”, descrevendo os recursos e linguagens para a Web Semântica, tal como mostrado na Figura 1.7.

Após a publicação do artigo sobre Web Semântica na Scientific American, em 2001, a área tem se desenvolvido bastante, onde o tema tem evoluído rapidamente, e seus resultados são divulgados em diversas conferências, periódicos, livros, grupos de pesquisa, entre outros tanto no Brasil quanto em outros países. Ocorreram vários avanços desde então em busca do desenvolvimento das camadas propostas por Tim Berners-Lee (Dubost and Herman, 2008). Entretanto, apesar de diversos trabalhos atuais ainda utilizarem esta perspectiva das camadas da Web Semântica, no ano de 2007 foi feita uma reavaliação das camadas propostas, descrevendo as tecnologias que foram recomendadas pelo W3C. A Figura 1.8 apresenta a nova perspectiva das camadas da Web Semântica.

Uma visão ainda mais atualizada sobre a pilha de tecnologias que envolve a Web Semântica é apresentada na Figura 1.9, mostrando toda a complexidade e tecnologias envolvidas com a área.

Como parte do desenvolvimento da Web Semântica, surgiu o conceito de Linked Data.
1.4 Dados Conectados e Dados Abertos Conectados
O Conceito de Dados Conectados (do Inglês Linked Data) pode ser definido como um conjunto de boas práticas para publicar e conectar conjuntos de dados estruturados na Web, com o intuito de criar uma “Web de Dados” (Bizer, et al., 2006). Estas práticas são fundamentadas em tecnologias web, como HTTP (Hypertext Transfer Protocol) e URI (Uniform Resource Identifier), com o objetivo de permitir a leitura dos dados conectados, de forma automática, por agentes de software. A Web de Dados cria inúmeras oportunidades para a integração semântica dos próprios dados, motivando o desenvolvimento de novos tipos de aplicações e ferramentas, como navegadores e motores de busca. Ao se observar as camadas da Web Semântica, os Dados Conectados podem ser considerados como descrito na Figura 1.10. Observemos também que na Figura 1.9, os Dados Conectados também estão presentes, porém representando uma pequena parcela das tecnologias que compõem a Web Semântica.

Para um melhor entendimento sobre a Web de Dados, pode-se estabelecer um paralelo entre a Web de Documentos (a Web atual) e a Web de Dados. A primeira faz uso do padrão HTML para acessar dados, enquanto que na segunda os dados são acessados a partir do padrão RDFResource Description Framework). Na Web de Documentos, hiperlinks são usados para navegar entre as páginas, enquanto que na Web de Dados os links RDF são usados para acessar dados de diversas fontes.
A Web de Documentos é baseada em um conjunto de padrões, incluindo: um mecanismo de identificação global e único, os URIs (Uniform Resource Identifier); um mecanismo de acesso universal, o HTTP e um formato padrão para representação de conteúdo, o HTML. De modo semelhante, a Web de Dados tem por base alguns padrões, como: o mesmo mecanismo de identificação e acesso universal usado na Web de documentos (os URIs e o HTTP); um modelo padrão para representação de dados, o RDF e uma linguagem de consulta para acesso aos dados, a linguagem SPARQL.
Na Figura 1.11, podemos visualizar no diagrama apresentando a relação que existe entre Web Semântica, Dados Conectados, RDF e os diversos formatos de dados estruturados.

Desta forma, os padrões de Dados Conectados permitem que qualquer pessoa publique os dados de uma forma que pode ser lido por pessoas e processado por máquinas. Isto é possível porque os dados que antes estavam “escondidos” na Web de Documentos estão agora acessíveis graças à utilização dos padrões supracitados para a conexão de dados. Esta conexão de dados permite que todos (homens e máquinas) possam trabalhar conjuntamente de forma mais eficiente (como no desenvolvimento de aplicações para os cidadãos com o objetivo de melhorar o transporte público). Os cenários de utilização como o motivado na Seção 1.1 apresentam o incrível potencial que os Dados Conectados podem proporcionar, desde negócios até a melhoria do sistema público. Dados Conectados que podem se integrar com os outros dados e consequentemente formar novos conhecimentos demonstram a importância de explorar esta área. Outro exemplo é uma das maiores empresas de comércio eletrônico, a Best Buy, conseguiu melhorar entre 15% a 30% no número de clicks via buscador Google para o seu site através da utilização do formato de serialização de Dados Conectados, RDFa.
A área de Dados Conectados surgiu no ano de 2006, através da publicação, também por Tim Berners-Lee, do documento Design Issues (Berners-Lee, 2006), com uma subseção de Web Semântica exclusiva para Dados Conectados. Em menos de uma década, empresas como (Wood, et al., 2014): i) a Google anunciou a utilização do formato de serialização JSON-LD para o Gmail, ii) IBM anunciou que o Banco de Dados DB2 se tornará um servidor de Dados Conectados; iii) Facebook expôs os Dados Conectados via Graph API; iv) BBC usou Dados Conectados para gerar páginas de três de seus produtos; v) o Governo Britânico disponibiliza vários de suas fontes de dados em formato RDF (Data.gov, 2014).
O termo “Dados Conectados” se refere a um conjunto de boas práticas para publicação e conexão de dados estruturados na Web, usando padrões internacionais recomendados pelo W3C. É importante frisar que “Dados Conectados” não necessariamente precisam ser abertos. Por exemplo, uma entidade privada pode conectar dados, mas não necessariamente deixá-los abertos, como é o caso da Open Corporates, que possui a maior base conectada de corporações do mundo. Outro exemplo é querer disponibilizar dados de forma conectada através de Capability URLs (Tennison, 2014) com o objetivo de“esconder” dados que sejam de acesso privado. Um novo conceito que vem surgindo e que já possui uma agenda de pesquisa é chamada de Dados Fechados Conectados (Cobden et al., 2011). Apesar de iniciativas em Dados Conectados de forma fechada, muitas iniciativas (principalmente governamentais) estão se preocupando a conexão e publicação dos dados de forma aberta. Esta visão fica bastante clara ao se observar os princípios propostos por Tim Berners-Lee. Estes princípios são conhecidos como “Sistema de 5 Estrelas” (vide Figura 1.12), que classifica por meio de estrelas o grau de abertura dos dados. Quanto mais aberto, maior o número de estrelas para os dados e maior facilidade para ser enriquecido (conectado).

As 5 estrelas para Dados Abertos são.
1. Disponível na Internet (em qualquer formato. Por exemplo: PDF), desde que com licença aberta, para que seja considerado Dado Aberto;
2. Disponível na Internet de maneira estruturada (em um arquivo Excel com extensão XLS);
3. Disponível na Internet, de maneira estruturada e em formato não proprietário (CSV em vez de Excel);
4. Seguindo todas as regras acima, mas dentro dos padrões estabelecidos pelo W3C (RDF e SPARQL): usar URL para identificar coisas e propriedades, de forma que as pessoas possam direcionar para suas publicações;
5. Todas as regras acima, mais: conectar seus dados a outros dados, de forma a fornecer um contexto.
Como dito anteriormente, é aconselhável que os dados sejam abertos considerando no mínimo 3 estrelas, porém estamos interessados neste documento em dados abertos a partir de 4 estrelas. A seguir, replicamos uma relação de benefícios da publicação de dados seguindo a classificação das 5 estrelas tanto para quem publica quanto para quem os consome (W3C Brasil, 2013):
TABELA 1.1
BENEFÍCIOS DA PUBLICAÇÃO DE DADOS (W3C Brasil, 2013)
| Estrelas | Quem consome | Quem Publica |
|---|---|---|
| ★ |
|
|
| ★★ |
|
|
| ★★★ |
|
|
| ★★★★ |
|
|
| ★★★★★ |
|
|
Podemos nos perguntar: a aplicação destes princípios está realmente sendo feita pelas instituições e estes padrões são realmente aplicados? Será que as pessoas estão de fato conectando os dados aos dados de outras pessoas?
Além dos exemplos de grandes corporações e governos (como Google, Facebook, Best Buy, Governo Britânico, entre outras) que já citamos aqui, podemos apresentar também o The Linked Open Data (LOD) Project, um projeto da comunidade de Web Semântica, iniciado em 2007 por um Grupo de Interesse do W3C. O objetivo do projeto foi fazer com que os dados fossem livremente disponibilizados para todos. A Figura 1.13 apresenta o último grafo gerado pelo LOD Project.


Cada círculo (nó) representa um vocabulário criado em RDF e cada seta (arco) representa uma conexão entre os vocabulários. Observe que o nó central na cloud apresentada equivale à DBPedia, que extraiu todos os dados da Wikipedia e disponibilizou em formato RDF para que qualquer um pudesse se conectar as suas aplicações. Uma empresa que fez uso do DBpedia foi a BBC. As cores dos nós representam áreas que classificam os dados (e.g. publicações, ciências da vida, geográficas, governo, mídias)
Apesar de alguns desenvolvedores consideraram a especificação de dados utilizando o padrão RDF pouco atraente e complexa, veremos aqui que podemos fazer isto de forma sistemática. O Grupo de Trabalho do W3C de Dados Abertos Governamentais definiu e publicou um conjunto de boas práticas para a publicação de dados conectados. Só para citar um exemplo (pois não é interesse deste capítulo estressar este tema), apresentamos a Figura 1.14 que descreve uma série de etapas para a geração publicação e exploração de dados abertos governamentais.
FIGURA 1.14
PROCESSO PARA PUBLICAÇÃO DE DADOS ABERTOS (Villazón-Terrazas, et al., 2011)
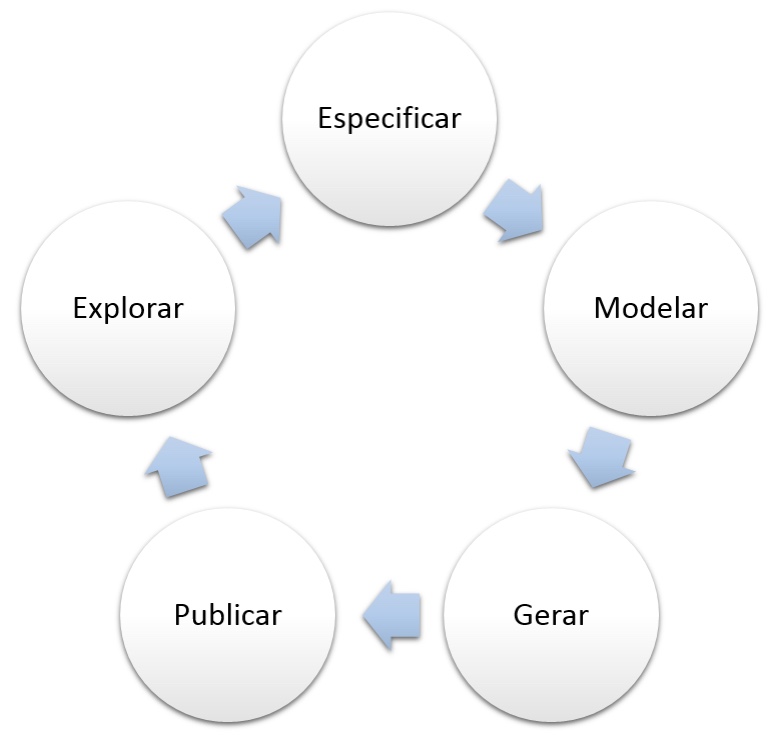
No total foi definido um conjunto de 10 boas práticas para a publicação de dados abertos conectados, sendo elas (Hyland, et al., 2014):
1. Preparar os Stakeholders: esta etapa é voltada para a formação dos usuários que irão criar e manter os Dados Abertos Conectados;
2. Selecionar o Conjunto (Fonte) de Dados: etapa dedicada a definir que se pretende abrir e conectar a outros dados e disponibilizá-los para reuso;
3. Modelar os Dados: com os Stakeholders capacitados e o conjunto de dados definidos, começa-se a etapa de modelagem dos Dados Conectados. Ou seja, como iremos representar os dados e como eles se relacionam com outros dados e de forma independente de aplicação;
4. Especificar a Licença: nesta etapa a equipe/organização, responsável pelos dados que serão abertos deve definir e especificar a licença que será usada;
5. Nomear bons URIs: esta etapa é o núcleo dos Dados Abertos Conectados e a definição e uso de boas práticas para URIs é fundamental;
6. Usar Vocabulários Padrões: uma das melhores formas de conectar dados é através do reuso de vocabulários conhecidos (e.g. Recomendações do W3C);
7. Converter os Dados: Uma vez que a estratégia de modelagem, as boas práticas para URIs foram definidas e os vocabulários a serem reusados foram identificados, vem a etapa de converter os dados da fonte original para representação adequada aos Dados Conectados;
8. Prover acesso aos Dados: esta etapa define quais serão as formas de acesso que seres humanos e máquinas terão aos dados;
9. Anunciar novo conjunto de Dados Conectados: de nada adianta conectar os dados e não anunciar para a sociedade que os mesmos foram disponibilizados. Desta forma, esta etapa cumpre este papel de divulgação do novo Dataset publicado;
10. Reconhecer a função social: esta etapa é definida para que o responsável por publicação dos dados cumpra a função de manter os dados publicados ao longo do tempo.
Como observamos, o processo de abertura de dados envolve várias etapas e bastante critério ao publicar e anunciar para a sociedade. Abordaremos neste documento cada uma destas etapas supracitadas e mostraremos como publicar e desenvolver estas aplicações. Ou seja, estamos interessados tanto em quem publica os dados quanto em quem consome os dados.
1.5 Considerações Finais
O principal objetivo deste capítulo foi oferecer ao leitor uma visão geral sobre dados abertos, considerando todo o seu ciclo de vida. Foi também intenção deste capítulo dissertar sobre como o conceito de dados abertos pode ser ampliado e potencializado para Dados Conectados. Esperamos que as seguintes mensagens tenham sido passadas:
• Compreensão sobre a importância de dados abertos e abertura de dados;
• Entendimento sobre a integração do conceito de dados abertos com Dados Conectados;
• Aprendizado sobre os benefícios de abertura e publicação de dados;
• Compreensão sobre o ciclo de vida para publicação de dados.