5 Desenvolvimento de Aplicações Semânticas
Introdução
Vimos nos capítulos anteriores que a Web atual ainda é composta por grande quantidade de páginas estáticas ou dinamicamente geradas, as quais se interligam e as pessoas podem lê-las e compreendê-las. Todavia os dados contidos nessas páginas não possuem um significado associado de modo a possibilitar sua interpretação por parte dos computadores. Nesse cenário, abordamos os conceitos de Web Semântica, cuja ideia original é estender a Web atual, descrevendo os dados e documentos atuais para que máquinas possam também entender e processar essa vasta coleção de informações (Cardoso et al., 2007) . Nessa perspectiva, a Web Semântica trará estrutura para o significado do conteúdo presente nas páginas web , criando um ambiente em que agentes de software percorrem página por página, que proporciona a facilidade de realizar tarefas sofisticadas para os usuários finais, tais como agendamento de consultas médicas ou compras de pacotes de turismo. Tim Berners-Lee propôs um modelo de camadas que foi e ainda é revisto pelo World Wide Web Consortium (W3C), apresentado na Figura 1.8, no qual os principais componentes eram RDF, RDFS, OWL e SPARQL. Já na Figura 1.9, foi apresentada uma nova versão das camadas da Web Semântica, criada por Benjamin Nowack.
Apesar da Figura 1.9 tornar mais claras a distribuição de conceitos e a forma de uso de cada tecnologia, as formas de desenvolvimento de aplicações semânticas variam e dependem do propósito de uso. A Figura 5.1 apresenta um mapa conceitual descrevendo os conceitos e principais ferramentas de apoio ao desenvolvimento de aplicações baseadas em Ontologias. Cada um dos conceitos apresentados na Figura 5.1 são explicados ao longo deste capítulo. O objetivo deste capítulo é apresentar como desenvolver aplicações semânticas por meio da utilização de dados abertos.

5.2 Padrões de desenvolvimento
A manipulação de instâncias é um importante passo no processo de desenvolvimento de aplicações baseadas em ontologias. Atualmente, existem duas abordagens principais utilizadas pelas ferramentas: desenvolvimento em triplas RDF e desenvolvimento orientado a objetos. Nas próximas seções, serão apresentadas as principais distinções e benefícios das abordagens mencionadas.
5.2.1 Desenvolvimento orientado a triplas RDF
A maioria das APIs atuais ainda trabalha com o desenvolvimento baseado em triplas RDF (Holanda et al., 2013; Dermeval et al., 2015b). Dessa forma, os desenvolvedores da aplicação devem estar cientes de como funciona a ontologia em RDF para poder manipular os dados mediante cada tripla (sujeito, predicado e objeto) em código.
Para exemplificar, caso se deseje adicionar na ontologia um recurso (sujeito) com várias propriedades inerentes a ele, são necessárias diversas linhas de código representando cada tripla do recurso, as quais capturam um único valor de cada propriedade. Similarmente, caso se deseje remover esse recurso, várias triplas devem ser removidas.
Por exemplo, várias linhas de código são necessárias para criar a instância Alice, da classe Person com a propriedade de name tendo valor “Alice”, usando a API do Sesame, que manipula instâncias mediante o desenvolvimento baseado em triplas RDF. A Figura 5.2 ilustra como adicionar esse recurso em um repositório do Sesame.

5.2.2 Desenvolvimento orientado a objetos
Diferentemente de triplas RDF, aplicações orientadas a objetos manipulam dados por meio de objetos e seus atributos. Tais objetos são caracterizados por um conjunto de atributos e valores. Nesse sentido, faz-se necessária uma ferramenta que “traduza” as operações em objetos para a infraestrutura de triplas RDF da camada inferior. Algumas ferramentas foram criadas para prover esse paradigma para manipulação de instâncias em ontologias.
Com isso, os desenvolvedores não precisarão ter um conhecimento profundo da linguagem de representação da ontologia. Um objeto no código representa uma instância na ontologia, seus atributos são mapeados com as propriedades das instâncias e as classes em RDF se tornam classes na linguagem de programação. Logo, para adicionar um recurso da ontologia, basta adicionar o objeto, facilitando, assim, o desenvolvimento dessas aplicações. Em comparação com o exemplo do Sesame (Figura 5.2), a Figura 5.3 ilustra o mesmo recurso, sendo adicionado ao repositório do Sesame usando a ferramenta Alibaba, que permite o desenvolvimento baseado no paradigma de orientação a objetos.

5.3 Ferramentas para desenvolvimento de aplicações semânticas
Nesta seção, serão detalhadas algumas categorias de ferramentas que auxiliam o desenvolvedor a construir um sistema semântico, sendo responsáveis por determinada função na aplicação. Além disso, alguns exemplos de ferramentas em cada categoria serão apresentados e sempre que possível serão feitas analogias com sistemas de informação tradicionais que utilizam bancos de dados relacionais.
5.3.1 Plataformas para publicação de dados
Dentre as plataformas para publica çã o de dados, destacam-se tr ê s, sendo elas: CKAN, Socrata e Junar. O CKAN é uma plataforma de c ó digo aberto para publica çã o, compartilhamento, pesquisa e uso de dados. Com o CKAN é poss í vel publicar, por meio de interface Web ou de uma API, dados como imagens, documentos e dados geoespaciais, permitindo que os mais diversos organismos (privados ou p ú blicos) utilizem essa ferramenta para publicar suas informa çõ es para toda a sociedade. Assim como na publica çã o, a ferramenta permite que as informa çõ es armazenadas por ela sejam recuperadas por interface Web bem como por API. O CKAN é extens í vel, permitindo que sejam criados plug-ins para estender suas funcionalidades, personaliz á vel, possui versionamento dos cat á logos de dados, permite o reuso de tecnologias existentes e é multilinguagem.
Assim como o CKAN, o Socrata é uma plataforma para publica çã o, compartilhamento, pesquisa e consumo de dados. Constru í do com as tecnologias mais recentes, o Socrata utiliza MongoDB e Elasticsearch e disponibiliza uma API para a publica çã o e consumo de dados. O Socrata disponibiliza ainda um conjunto de bibliotecas e SDK para o desenvolvimento de clientes em v á rias linguagens, tais como: R, PHP, Java, Objective-C e outros. Atualmente existem duas vers õ es para o Socrata, sendo uma para a comunidade Open Source e outra para uso privado. Por fim, o Junar é uma plataforma de c ó digo fechado e pago, que cobre tamb é m todas as etapas do processo de publica çã o de dados.
5.3.2 Frameworks para manipulação de RDF
A primeira ferramenta de que se necessita ao construir um sistema baseado em ontologias são as APIs, que oferecem a manipulação de triplas RDF e a conexão com o banco de dados RDF. Tais ferramentas funcionam como middlewares entre a aplicação e a ferramenta triplestore. Portanto, elas têm a mesma responsabilidade que um Java Database Connectivity (JDBC), com a diferença de que, na área de ontologias, essas ferramentas geralmente possuem um banco de dados RDF próprio. As APIs Sesame (Broekstra et al., 2002) e Jena (McBride, 2002) são as duas mais populares nessa categoria.
Sesame é um arcabouço Java para armazenamento e consulta em dados RDF. O Sesame é bem extensível e configurável no que diz respeito aos mecanismos de armazenamento (memória principal, arquivos binários ou banco de dados relacional), máquinas de inferência (RDFS), formatos de arquivo de ontologias (OWL, RDF ou N3) e linguagens de consulta (SPARQL e Sesame RDF query language). O Sesame oferece uma API para o usuário para que este possa ter acesso a seus repositórios, bem como uma interface HTTP que suporta o protocolo SPARQL. Várias extensões para o arcabouço foram desenvolvidas por terceiros.
Sesame é a principal ferramenta utilizada neste trabalho. Sua escolha deve-se à alta flexibilidade da API, que é uma das mais populares quando se trabalha com Web Semântica e ontologias. Além disso, a interface HTTP que o Sesame provê é muito útil para visualizar os dados que estão sendo manipulados durante o desenvolvimento.
Outra vantagem do Sesame é que, por ser extensível, o mecanismo de armazenamento pode ser alterado sem que haja qualquer impacto na aplicação construída com o Sesame. Dessa forma, pode-se desfrutar de toda a potencialidade da API e usar um repositório de alta performance como OWLIM ou Virtuoso.
O Jena é um framework para construção de aplicações semânticas. Jena também é uma coleção de ferramentas e bibliotecas Java com o objetivo de suportar o desenvolvimento de sistemas baseados na Web Semântica. A ferramenta inclui: uma API para leitura e escrita de dados RDF em arquivos; uma API para manipulação de ontologias em OWL e RDFS; um motor de inferência baseado em regras para raciocínio; mecanismos de armazenamento de grandes volumes de dados em triplas RDF; e um motor de consulta conforme a nova especificação do SPARQL.
5.3.3 Bancos de dados RDF
A segunda categoria a ser descrita possui as ferramentas que são responsáveis por armazenar RDF em algum tipo de banco de dados. Essas ferramentas são conhecidas por diversos nomes, como banco de dados RDF, triplestore e repositórios de ontologias, entre outros. Em comparação com sistemas de informação tradicionais, essas ferramentas são similares aos Sistemas de Gerenciamento de Banco de Dados (SGBD). Contudo apenas algumas ferramentas utilizam bancos de dados relacionais para armazenar as triplas em RDF (caso do Virtuoso); as outras utilizam um sistema de índice de arquivos (caso do OWLIM). A seguir, três bancos de dados RDF serão apresentados: OWLIM, Virtuoso e AllegroGraph.
OWLIM é uma extensão do Sesame que possui uma diversidade de repositórios semânticos (Kiryakov et al., 2005) . Esses repositórios possuem características como: armazenamento de RDF implementado em Java; alta performance; suporte à inferência das representações RDFS e OWL; escalabilidade e balanceamento de carga. OWLIM possui três versões de repositórios:
• OWLIM-Lite: é o repositório de maior performance e o único grátis. Apesar de ser em memória principal, ele possui um mecanismo de persistência em arquivos binários. Além disso, ele suporta inferência com dezenas de milhões de triplas mesmo em desktops atuais.
• OWLIM-SE: é o repositório de maior escalabilidade. Esse repositório possui suporte à inferência e alta performance em consultas concorrentes. Ademais, ele consegue operar com o carregamento de dezenas de bilhões de triplas.
• OWLIM-Enterprise: é uma infraestrutura de cluster baseada nos repositórios do tipo OWLIM-SE. Esse repositório oferece infraestrutura escalável mediante o alto desempenho paralelizando consultas. Também oferece o balanceamento de carga e recuperação automática de falhas.
O Virtuoso é um servidor multiprotocolo que provê acesso ao banco de dados relacional interno por meio de ODBC/JDBC. Além de possuir um motor de busca SQL, o Virtuoso possui um servidor HTTP para usuários administradores, com terminais em diferentes protocolos (ex. serviços web) e linguagem de script interna (Erling; Mikhailov, 2010) .
Como o propósito do Virtuoso é ser um banco de dados universal, foi realizada uma adaptação para suportar o armazenamento em triplas RDF. Nessa perspectiva, a ferramenta mapeia as triplas RDF em tabelas dentro do seu banco de dados relacional. O Virtuoso também oferece um motor de busca em SPARQL (com suporte a nova especificação 1.1), que “traduz” as consultas em SPARQL feitas pelo desenvolvedor para a correspondente em SQL.
Assim como o OWLIM, o Virtuoso possui uma versão grátis; não bastasse isso, é código aberto. A grande diferença dessa versão para as versões pagas do Virtuoso é que as pagas possuem a opção de cluster . O Virtuoso provê drivers de acesso tanto usando a API do Sesame como a do Jena.
AllegroGraph é um banco de dados RDF moderno e de alta performance (Aasman, 2006) . A ferramenta possui um mecanismo de persistência que faz uso, de maneira eficiente, da memória em combinação com o armazenamento interno baseado em disco. Dessa forma, AllegroGraph pode ser escalado para o armazenamento de bilhões de triplas RDF mantendo uma boa performance.
AllegroGraph também possui um motor de busca em SPARQL, inclusive suportando a nova especificação 1.1. Além disso, a ferramenta oferece suporte ao raciocínio em construtores RDFS e uma interface administrativa com diversos recursos. A versão grátis do AllegroGraph é limitada ao armazenamento de 5 milhões de triplas; acima disso é necessário comprar a versão Enterprise .
5.3.4 Sistemas de mapeamento objeto-ontologia
Finalmente, a última categoria de ferramenta a ser detalhada nesta seção engloba os sistemas de mapeamento objeto-ontologia (OOMS). Esse tipo de ferramenta tem como função facilitar o desenvolvimento da aplicação semântica, ao permitir que o desenvolvedor foque na lógica da aplicação. Assim, não é necessário escrever códigos para conexão com o banco de dados RDF nem acessar os dados via triplas RDF, preservando as características de orientação a objetos da linguagem de programação.
Como o próprio nome refere, um sistema de mapeamento objeto-ontologia cria classes na linguagem de programação correspondentes às entidades em uma ontologia. Portanto, instâncias dessas classes podem ser representadas na aplicação como objetos. Em sistemas de informação que usam bancos de dados relacionais, essas ferramentas são chamadas de sistemas de mapeamento objeto-relacional (ORMS), sendo alguma delas já bem consolidadas e amplamente utilizadas como a ADO.NET (Esposito, 2002) e o Hibernate (Bauer; king, 2006) . Na área de ontologias, já existem algumas ferramentas, como o Jastor, Empire, Elmo/Alibaba e o JOINT.
Jastor é um gerador de código Java que cria JavaBeans 75 a partir de ontologias descritas em OWL (Szekely; Betz, 2006) . Com isso, os desenvolvedores podem convenientemente acessar uma ontologia armazenada em um modelo do Jena (vide Seção 2.4.2). O Jastor consegue gerar interfaces Java, suas implementações e fábricas, tudo baseado nas propriedades e hierarquia de classes descritas na ontologia.
Empire é uma implementação da Java Persistence API (JPA) para RDF, mediante o mapeamento de objeto-ontologia, permitindo consultas de bancos de dados RDF (armazenamento em triplas) com a linguagem SPARQL ou Sesame SeRQL (Grove, 2010) . JPA é uma especificação para gerenciamento de objetos Java, normalmente usada em conjunto com um RDBMS (padrão da indústria para ORMS em Java). Esse mapeamento de classes Java para triplas RDF é obtido por meio do uso de anotações JPA padrões, as quais são estendidas com algumas especificações RDF, seja para namespaces , classes RDF ou propriedades RDF. A ferramenta Empire provê um framework de persistência em Java para uso em projetos da Web Semântica, nos quais os dados são armazenados em RDF. Ao oferecer uma implementação do JPA, a ferramenta abstrai a manipulação de dados em RDF. Contudo o objetivo maior da ferramenta é substituir implementações JPA existentes para bancos de dados relacionais, ao simplificar a mudança desses sistemas para sistemas baseados em modelos RDF. O Empire faz uso da API do Sesame para manipulação em triplas RDF, mas o desenvolvedor pode configurar um parser para operar o Empire com a API do Jena.
O Elmo é um gerenciador de entidades RDF que mapeia implementações JavaBeans em triplas RDF para repositórios Sesame (Mika, 2007) . Elmo provê interfaces Java estáticas para recursos RDF, ou seja, o desenvolvimento de aplicações com Elmo é feito mediante orientação a objetos centrada no sujeito. Por ser um sistema orientado a objetos, ele disponibiliza um modo de agrupar comportamentos comuns e separar papeis dentro de interfaces e classes. Os modelos gerados pelo Elmo são simples em expressar os conceitos envolvidos. O AliBaba foi desenvolvido como o sucessor do Elmo e, portanto, usa princípios similares a este para o mapeamento de objeto-ontologia. Assim como as outras ferramentas, o Alibaba é uma implementação de sistema objeto-ontologia centrada no sujeito da tripla RDF. Além disso, a ferramenta oferece implementações RESTful de bibliotecas cliente e servidor para armazenamento distribuído de documentos e metadados RDF.
Na próxima seção, discutiremos sobre o OOMS JOINT.
5.4 Desenvolvimento de uma aplicação semântica usando o JOINT
O JOINT é um toolkit Java código aberto que oferece um gama de funcionalidades para facilitar o desenvolvimento de aplicações baseadas em ontologias (Holanda et al., 2013). Esse toolkit permite, por exemplo: manipulação de ontologias em um repositório, consultas na linguagem SPARQL e manipulação de instâncias por meio do paradigma de orientação a objetos. O JOINT fornece uma API para bancos de dados RDF parecida com o Hibernate para bancos de dados relacionais.
Inicialmente, o JOINT foi desenvolvido pelo Núcleo de Excelência em Tecnologias Sociais da Universidade Federal de Alagoas (NEES – UFAL) como um mecanismo de persistência para aplicações de pesquisas desenvolvidas na época em doutorados e mestrados. Em 2012, o JOINT se tornou oficialmente um projeto de pesquisa ao ser financiado pelo W3C Brasil/NIC.br/CGI.br. Atualmente, o JOINT é mantido principalmente pelo NEES, em cooperação com o Laboratório de Computação Aplicada à Educação e Tecnologia Social Avançada da Universidade de São Paulo (CAEd – USP), desenvolvedores do MeuTutor e da Linked Knowledge, e com um número de voluntários que contribuem com ideias, descobertas de bugs e reparos.
5.4.1 O padrão KAO
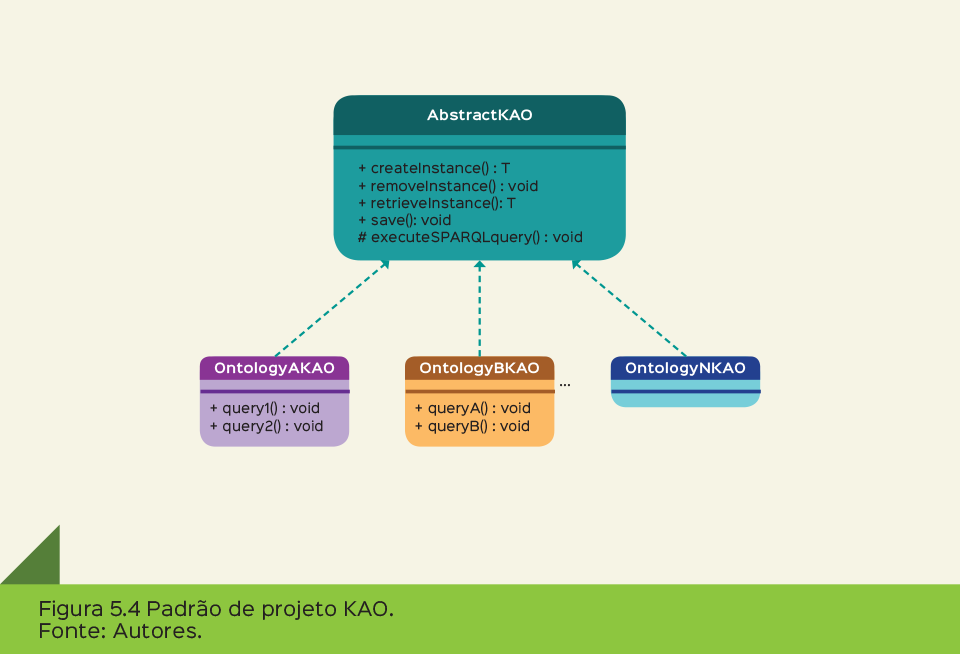
O JOINT trabalha com o conceito do Knowledge Acess Object (KAO), o qual é um padrão de persistência similar ao Data Acess Object (DAO), com a diferença de que o KAO não trabalha somente com dados, mas com informação e conhecimento. Dessa forma, esse padrão pode separar a camada de negócios da aplicação da camada de acesso ao repositório semântico. Além disso, o KAO tem o objetivo de desacoplar os métodos de criação, remoção e recuperação de instâncias dos métodos de consulta em SPARQL. Portanto foi criada uma classe abstrata (AbstractKAO) que inclui a implementação dos métodos citados. Então para cada ontologia é criada uma classe concreta que herda a classe AbstractKAO, nessa classe concreta são implementados apenas métodos que envolvem consultas em SPARQL referentes à ontologia em questão, possibilitando a evolução do código da aplicação. A Figura 5.4 ilustra o padrão.
5.4.2 Obtendo e configurando o JOINT
Versões do JOINT podem ser baixadas a partir do SourceForge. Existem duas opções de download. A escolha deve ser feita dependendo do uso que será feito do JOINT:
• Joint-jdk.tar.gz: Esse é um arquivo .tar zipado para sistemas GNU contendo todo o código binário do kit de desenvolvimento do JOINT. Ele inclui todas as bibliotecas que o JOINT usa, assim como uma documentação.
• Joint-jdk.zip: Esse é um arquivo .zip que contém os mesmos arquivos do arquivo tar.gz.
• Joint.jar: Esse é um arquivo Java (.jar) encapsulando tudo do JOINT. O objetivo desse arquivo é facilitar a inclusão do JOINT no projeto Java da aplicação a ser desenvolvida. Só é necessário adicionar esse arquivo ao projeto para poder usar a API do JOINT.
Para configurar o ambiente de desenvolvimento para uso do JOINT, os usuários deverão executar apenas dois passos. O primeiro passo é a inclusão da biblioteca do JOINT, mencionada anteriormente, no classpath da aplicação Java. Com isso todas as operações do JOINT podem ser acessadas pelo código da aplicação. O segundo passo é a configuração do repositório que será acessado pelo JOINT. Para isso, primeiro o desenvolvedor deverá criar um arquivo de propriedades na raiz do projeto com o nome Repository.properties. Depois, o desenvolvedor deverá criar uma classe concreta em seu projeto que implemente a interface RepositoryConfig do JOINT, que possui um método createRepository. Esse método deve retornar um objeto do tipo Repository do Sesame, permitindo a flexibilidade de configuração do repositório proveniente da API do Sesame. O local dessa classe criada deve ser especificado no arquivo Repository.properties.
5.4.3 Operações com ontologias no repositório
Para acessar a maioria das operações permitidas pelo JOINT, os desenvolvedores fazem uso da sua fachada: RepositoryFacade . Vale ressaltar que essas operações são feitas no repositório especificado na seção anterior. Para adicionar uma ontologia é utilizado o método addOntology , no qual o primeiro parâmetro é o caminho da ontologia e o segundo é o URI da ontologia. Para atualizar uma ontologia no repositório pré-definido, chama-se o método updateOntology com os mesmos parâmetros do método anterior. Por fim, para remover uma ontologia do repositório, basta usar o método deleteOntology passando apenas um parâmetro que é o URI da ontologia, como apresentado na Figura 5.5.

5.4.4 Gerando código a partir de ontologias
Logo após a persistência das ontologias, os desenvolvedores usam a ferramenta para gerar código Java a partir delas, possibilitando, assim, a manipulação de instâncias por meio das operações de criação, atualização, remoção e recuperação. O código desse gerador é uma extensão do da ferramenta Alibaba.
A linguagem Java não suporta herança múltipla, ou seja, um objeto só pertence a uma determinada classe, não podendo ser uma instância de duas ou mais classes. Em contrapartida, indivíduos de uma ontologia podem ter múltiplos tipos associados a eles. Portanto, a solução encontrada pela ferramenta Alibaba foi gerar interfaces Java, uma vez que estas permitem a herança múltipla. Assim, uma interface Java pode herdar duas ou mais interfaces. Para implementar tais interfaces, a ferramenta Alibaba gera, em tempo de execução, proxie s dinâmicos para que os desenvolvedores só possam acessar e manipular as interfaces geradas.
O JOINT usa um gerador de código do Alibaba modificado e evoluído com o objetivo de não apenas gerar interfaces Java, porém classes concretas que implementam cada interface. Desenvolvedores ainda acessam e manipulam apenas as interfaces, porém em vez de criar proxies dinâmicos em tempo de execução, JOINT retorna um objeto da classe que implementa a determinada interface. Isso resulta, teoricamente, em uma menor sobrecarga da ferramenta em termos de desempenho, pois, em vez de criar implementações em tempo de execução com proxies , a ferramenta usa códigos pré-compilados com as classes concretas geradas. Veja como gerar código Java automaticamente a partir de ontologias na Figura 5.6.

Como evidencia o exemplo, a fachada da ferramenta deve ser inicializada, para que as operações da ferramenta possam ser utilizadas. O primeiro parâmetro do método getOntologyCompiler (retorna uma instância da classe que compila a ontologia em Java) é o caminho do arquivo .jar que se deseja gerar com as classes da ontologia. O segundo parâmetro é uma lista de URLs de cada ontologia. Se a ontologia estiver na Web, coloca-se o protocolo “http://...”; se for um arquivo local do computador coloca-se “file://...”. Em seguida, basta chamar o método compile para gerar o arquivo .jar.
5.4.5 Criando um KAO
Como mencionado anteriormente, para cada ontologia que se deseja manipular instâncias e executar consultas SPARQL, é necessária a criação de um KAO respectivo a essa ontologia. Nas próximas subseções vamos utilizar a ontologia programmes da BBC por motivos de exemplificação. Já que queremos manipular instâncias ou até mesmo consultar a ontologia, cria-se uma classe concreta que herda a classe AbstractKAO representando a ontologia BBC. A Figura 5.7 apresenta o código da nova classe criada.

Ao herdar a classe AbstractKAO será necessário criar o construtor. Esse construtor deve ser genérico, recebendo como parâmetro uma classe pertencente à ontologia, que deve ser gerada pelo JOINT, e o URI da ontologia em questão. Essas variáveis devem ser passadas para o AbstractKAO com o comando super .
5.4.6 Manipulando instâncias com o CRUD
Para executar as operações de CRUD e fazer consultas em uma ontologia com o JOINT é necessária a criação de uma classe KAO representando a ontologia que deseja ser manipulada. No caso do exemplo da BBC, foi criada a classe ProgrammesBBCKAO , que herda a classe AbstractKAO .
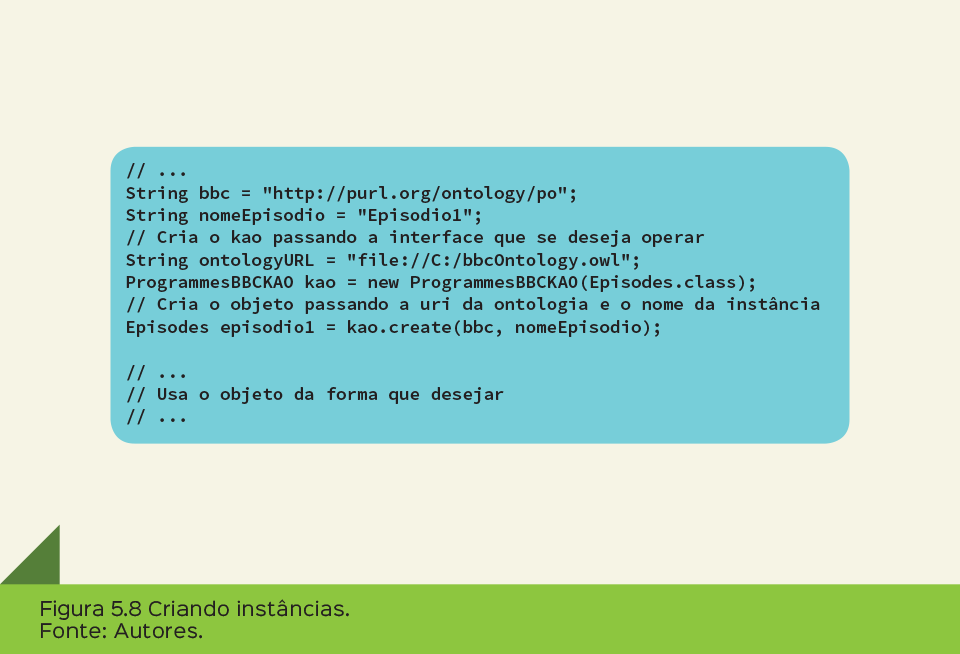
A Figura 5.8 mostra o código de criação de uma instância do tipo Episodes utilizando a ProgrammesBBCKAO . Primeiro cria-se um objeto da classe ProgrammesBBCKAO , passando por parâmetro a interface Episodes . Em seguida, também cria-se um novo objeto com o método create , passando como parâmetro o URI da ontologia BBC e o nome da instância. O sistema, então, gera a instância no repositório e retorna para o desenvolvedor um objeto com a implementação da interface passada (no caso do exemplo Episodes). A partir desse ponto, o desenvolvedor pode utilizar o objeto como ele desejar, ressaltando que as alterações feitas no objeto não irão refletir no repositório até que o objeto seja atualizado.
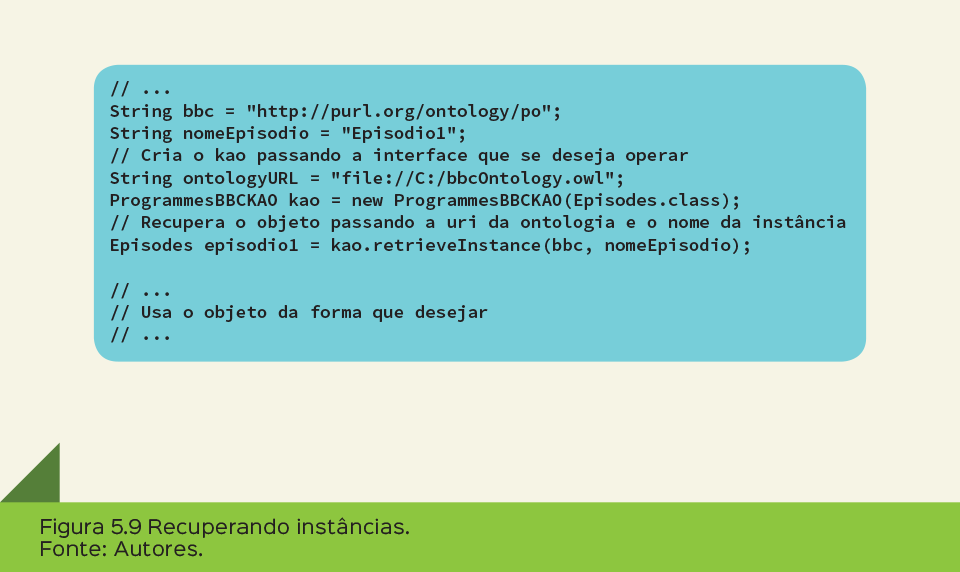
O código para recuperar uma instância contida no repositório é bastante similar ao de código de criação, mudando apenas o método chamado no KAO, como mostra a Figura 5.9. Vale ressaltar que a instância deve estar criada no repositório para poder ser recuperada.
A próxima operação a ser detalhada é a de atualização de instâncias. A Figura 5.10 indica na perspectiva do desenvolvedor, como atualizar uma instância. Embora nessa figura o objeto seja recuperado e atualizado pelo mesmo KAO, isso não é necessário. Na verdade, a instância pode ser recuperada em outra parte da aplicação do desenvolvedor, depois enviada por diversas camadas da arquitetura e alterada em alguma delas. No momento em que a aplicação devolve a instância para o KAO atualizar, ele recupera as mudanças feitas no objeto e sincroniza com os dados no repositório.

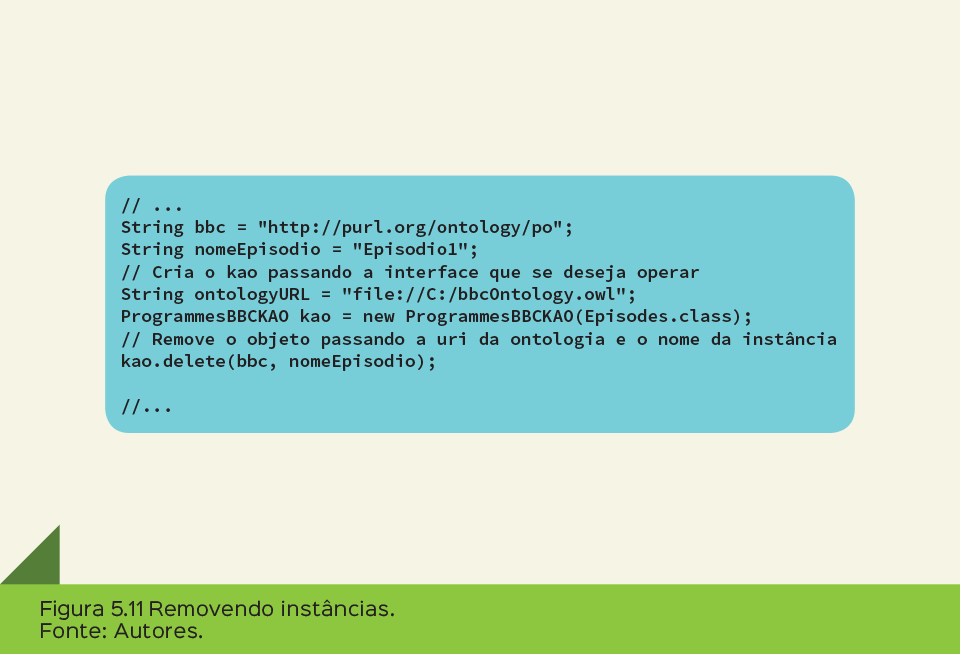
A última operação de CRUD é a de remoção de instâncias. Assim como nos métodos de criar e recuperar instância, o desenvolvedor cria um KAO passando a interface que ele deseja operar e, ao chamar o método delete, passa como parâmetros o URI da ontologia e o nome da instância. A Figura 5.11 mostra o código de remoção de instâncias na perspectiva do desenvolvedor. O método delete também pode ser chamado, desse modo, passando como parâmetro o próprio objeto a ser removido.
5.4.7 Executando Consultas
Ao usar consultas SPARQL em um repositório, o desenvolvedor, na maioria das vezes, consulta determinadas instâncias, ou seja, a consulta em SPARQL retorna uma ou um conjunto de instâncias. O JOINT provê que os retornos dessas consultas sejam também na forma de objetos. Para executar consultas SPARQL no JOINT, o usuário deverá criar métodos dentro do KAO que façam essas consultas (Figura 5.12).

Apesar dessa consulta retornar todas as instâncias da classe Episodes , esse mesmo resultado pode ser obtido usando o método retrieveAllInstances . Além disso, o desenvolvedor pode também criar um método de consulta genérico para receber uma String com a consulta e então executá-la, retornando o resultado (veja a Figura 5.13). Outros métodos de consultas SPARQL estão descritos na documentação Java da ferramenta 76 .

5.5 Considerações Finais
O principal objetivo deste capítulo foi oferecer ao leitor uma visão geral sobre desenvolvimento de aplicações utilizando tecnologias semânticas. Foi dado um destaque especial na Plataforma JOINT para o desenvolvimento de aplicações semânticas em Java. Esperamos que as seguintes mensagens tenham sido passadas:
• Compreensão sobre diferentes tecnologias para desenvolvimento de aplicações semânticas;
• Conhecimento sobre o desenvolvimento de aplicações através da manipulação de triplas RDF e objetos;
• Entendimento sobre o desenvolvimento de uma aplicação utilizando a plataforma JOINT.